The biggest technical challenge when using production data for development and testing is that the volume of data can be huge. Subsetting the data while keeping its semantic meaning is not an easy task.
In a practical sense relating to IT, subsetting is a process of making a large database smaller in order to ease the development and testing. Without it, teams would either have to works directly on production databases or each have his own copy of it, which when talking about enterprise solutions, could be well over the terabyte mark.

Challenges of subsetting
With subsetting, each team or even team member can have his own database with the data that is relevant to the task. But because of the new process, a lot of technical skill are required, most of which are not needed and shouldn’t be required from a tester or, for example, a UX designer:
- Knowledge of the SQL syntax
- In depth knowledge of the database schema and relationships
- The domain knowledge of the application, and what tables are needed for it to function
Because of all this, scarce resources have to be consumed, mostly database administrators and developers time. And it’s not a one-off process. Every time the database definition changes, the process must be updated, and the new subsets redistributed to users. Now add anonymization and pseudo anonymization because of the GDPR into the mix, and the task becomes extremely tedious.
What is a subset anyway?
We must decide what data we need, or to go down to the database level, what tables are the pivot for our subset building. Some of the possible strategies are:
- First, top, bottom or random N records
- Filter by columns of a table
- List of primary keys to extract
- Complex queries spanning over multiple tables
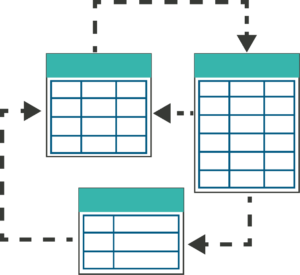
After that, we need to include all the related parent table data to the records we extracted so that when we bring the constraints in, the database is valid. We might also want some child records of the tables, with or without filters and then we must gather the remaining parents.

Figure 2 – Parent child relationships between tables
Data explosion
There will probably be tables that have circular references back to itself, either directly or via some sequence of tables. Here we can easily experience data explosion, if we run into a record that is connected to many other records, and we end up with a useless subset, that is almost as big as the original one.
Here we need to identify such records and tables, and either copy them entirely, which is usable for smaller tables like organization hierarchy, but for a very active table, like transactions in a banking system we need a cutoff. Some of the basic cutoff strategies available are:
- Don’t collect the data, we will deal with the constraint later, either by not collecting the records, or putting the appropriate key to null
- Link all the records to the same parent record, be it a random, fixed or syntactic record
Performance
There are many factors that can affect the performance, but the one we can influence is the number of queries to the database. We can make the queries smarter, try to minimize the number of visits of the same table, and perform micro optimizations by deciding how to transfer the data from one system to the other.
We can offload a lot of work to the machine running the subsetting, and have it log the Ids of row to be transferred, but then we run into a risk of needing a lot of memory. Or we can have the database engines run the queries for us utilizing linked servers, but then we can easily overextend the production database. It’s not an easy decision to make and each system is different.
Conclusion
Subsetting sounds trivial when first mentioned, but as you get deeper into it, it becomes more complex. As soon as you start working with real life database, a great number of challenges appear which are not easily solved. Considering that the users want an application that works and is thoroughly tested, subsetting should be an integral part of quality control, testing and DevOps.
If you’ve encountering the subsetting Gordian knot, and need help, or are just overwhelmed with the many details, come and find us at the Ekobit stand, and see how we, our software and our expertise in both data masking and subsetting can help you.