
It seems like everyone in the quality engineering community is talking about AI. After all, advances generative AI have been rapidly transforming our tools, frameworks, platforms, processes, and ways of working. AI-assisted software lifecycle activities are becoming more widespread and generally accepted.
However, while everyone has been busy applying AI to testing, myself and the team at Test IO have been focused on harnessing the collective intelligence of humans to validate and verify several different types of AI systems. Our approach is currently being utilized to test some of the most sophisticated AI models, assistants, co-pilots and agents at scale.
This article shares our approach to testing what we refer to as AI-infused applications. It describes the grand challenge with testing these types of applications and then discusses the need for human evaluation. After outlining a number of practical techniques, it provides some lessons learned on how to effectively scale the human evaluation of AI/ML.
AI-Infused Applications (AIIA)
Just as with any application, there are many different ways that an AI-based system can be implemented. The particular method used generally depends on the problem being solved, desired capabilities, and any constraints on its development and operation.
Some common approaches to developing AI systems are:
- Rules-Based AI. Encodes domain expertise into conditional (if-then-else) statements, heuristics, or expert systems.
- Classical Machine Learning. Training a supervised or unsupervised learning model from scratch using structured datasets and algorithms like random forests, support vector machines, or gradient boosting.
- Integrating a Pre-Trained Model. Leverages APIs from providers like OpenAI, Google, Anthropic, or Hugging Face to integrate an AI-powered component into an application with minimal development effort.
- Retrieval Augmented Generation. Combines LLMs with a vector search database to fetch relevant information before generating a response.
- Fine-Tuning a Pre-Trained Model. Uses transfer learning to adapt a pre-trained model to a specialized dataset to improve the performance of specific tasks.
- Agent or Multi-Agent Based AI. Builds autonomous agents using an LLM backend, goal-setting mechanisms, and tools for action execution, e.g., APIs, databases, browser automation. These types of systems may include reinforcement learning (RL) or emergent behavior to allow multiple AI agents to interaction, collaborate, or compete in an environment.
- AI-Orchestrated Workflows. Integrates multiple AI components using workflow orchestration tools such as LangChain, Haystack, or Airflow).
Each of these approaches have trade-offs in terms of accuracy, efficiency, cost, interpretability, among others. However, regardless of the approach used, as long as an application leverages AI or ML models or services as part of their logic, we consider it to be an AI-infused application.
Grand Testing Challenge
The rapid pace of growth in the AI space makes it particularly difficult to keep track of all of the different ways these types of systems can be implemented. However, irrespective of the development method, AI-infused applications present a grand challenge for software testing practitioners primarily due to their highly dynamic nature.
Dynamism
AI-infused applications exhibit different levels of dynamism depending on their purpose and capabilities. For example, there are dynamic aspects of predictive, adaptive, and generative AI systems which make them unpredictable, non-deterministic and, as a result, very difficult to test.
- Predictive AI analyzes historical data to identify patterns and make forecasts about future events or outcomes. These types of systems evolve with data. In other words, the accuracy of predictions depends on continuously updated data and therefore, as new data arrives, retraining or fine-tuning the model helps improve its forecasts. Some predictive systems like stock trading algorithms process real-time data streams, modifying forecasts as conditions change.
- Adaptive AI continuously learns from new experiences and environmental changes to modify its behavior and improve performance over time. Unlike traditional models, it evolves without requiring explicit reprogramming. For example, self-learning chatbots will personalize their responses over time. Systems like these are context aware and dynamically adjust based on real-world conditions. Adaptive AI can autonomously tweak its internal models and strategies to improve accuracy and efficiency over extended use.
- Generative AI creates new content such as text, images, code, and music based on learned patterns from vast datasets. The same user prompts sent to a model can generate different responses. Generative models can refine outputs based on user feedback, style preferences, leading to evolving content quality. Model knowledge can be augmented with external sources via retrieval augmented generation, making the overall system highly flexible.
Adequately testing AI systems may involve a combination of pre- and post release testing, continuous monitoring, automated pipelines, adversarial testing, and human evaluation. These approaches help address quality challenges with AI systems including model drift, bias, fairness, uncertainty, output-variability, explainability, hallucinations, and more.
The Importance of Human Evaluation
While automated testing methods for AI systems help to monitor performance, human evaluation is essential to ensure AI aligns with real-world expectations. Here’s why human evaluation is critical and some techniques that can be applied in practice.
Why It Matters
In classical ML systems, automated accuracy metrics such as F1 scores don’t necessarily capture the real-world impact of predictions. Bias and fairness issues often require domain experts to identify potential harms and when it comes to explainability, although some tools provide insights, human judgement is generally needed to interpret them meaningfully. If an AI-infused application is going to interact directly with users, the system must be assessed for user experience and usability.
Adaptive AI systems can potentially start optimizing on the wrong objectives. For example, a common problem with recommendation systems is that they tend to reinforce their own biases. Here’s how:
- Recommendation system suggests content based on past user behavior.
- User engages more with that types of content (e.g., specific movie genres, political articles)
- System interprets this as a strong preference, leading it to narrow future recommendations to similar content.
- Over time, diversity in recommendations decreases and users are less likely to be exposed to alternative perspectives.
Lastly, AI-generated content is often ambiguous, misleading, or biased, requiring human judgement to assess quality. Automated checks like toxicity filters generally can’t fully capture nuances like sarcasm, cultural sensitivities, and ethical concerns.
Practical Techniques
- User-Centric Testing. Real users provide feedback on how well AI adapts to changing needs and preferences.
- Fact-Checking Panels. Subject matter experts verify AI-generated claims for accuracy and credibility.
- Bias and Harm Assessment. Diverse human reviewers assess content for potential ethical issues and unintended harm.
- Human Scoring and Annotation. Evaluators rate AI outputs on quality criteria such as coherence, creativity, appropriateness, practicality, among others.
Effectively Scaling Human Evaluation of AIIAs
Over the past 14 months, the team at Test IO has been diligently focused on human evaluation of AI-infused applications for a variety of large enterprise clients. The AI-infused applications under test range from independent chat and voice bots, to code and cloud assistants integrated into software development environments and cloud platforms. So how do you make human evaluation scalable, structured, and reliable? Here are some of the key lessons we’ve learned along the way.
Establish Clear Evaluation Criteria
This involves defining structured rubrics for human reviewers to ensure consistency. Figure 1 shows a sample deliverable including a cross-section of quality criteria.
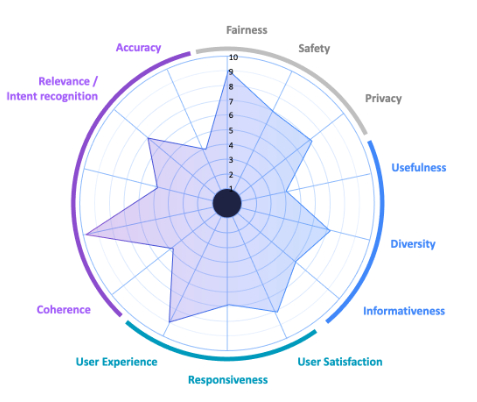
Figure 1: Quality Criteria Example Showing the Results of Human Evaluation of AIIAs
Leverage Internal and External Communities
Diverse human expertise may be crowdsourced internally from your own pool of people, or externally via user testing communities. As shown in Figure 2, we capture a diverse set of perspectives by using the Test IO crowdsourcing platform to run test cycles using internal employees or external freelancers, or a combination of the two.
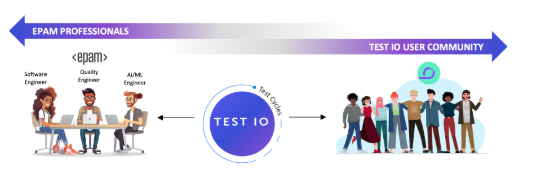
Figure 2: Access to Diverse Set of Human Evaluators including Internal Experts and External Freelancers
Combine Human and AI Judges
Automated tools or, for example, another LLM can be used for initial screening, followed by human reviewers for deeper analysis. Not only can this technique be applied to accelerate the evaluation activities, but it also facilitates comparing human versus automated evaluation. The confusion matrix in Figure 3 illustrates the correlation between human ground truths and labels generated by GPT4. Such an artifact can be used to indicate cases where the LLM assigns “irrelevant” to something that the human assigned as highly relevant, and vice-versa.
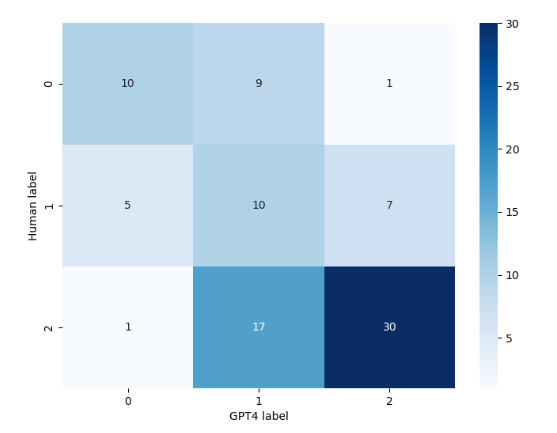
Figure 3: Confusion Matrix of Human Scores versus LLM Scores
Continuously Incorporate Human Feedback
Crowd-sourced human evaluation of AI-infused applications is applicable to several dimensions of testing. Test cycles can be exploratory, focusing on the early stages of app development or on new features. When issues are discovered, user feedback can be fed back into the model via approaches like reinforcement learning from human feedback. After the given model is updated or re-trained, test cycles can be executed as a form of regression using humans, automated tools, or a combination of both. Figure 4 provides a side-by-side comparison of these two general modes of conducting AIIA testing at scale using crowd sourcing.
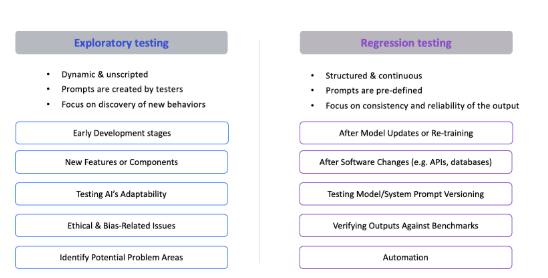
Figure 4: Crowd-Sourced Exploratory Testing and Regression Testing of AIIA
Conclusion
For now, AI systems are too complex and dynamic to be tested solely through automation. Human evaluation is indispensable for detecting biases, verifying real-world applicability, and ensuring an ethical and engaging user experience. By integrating structured human oversight and deploying it using a scalable outcome-based model, we can look towards a future where AI systems are not only technically robust, but also aligned with societal values and user expectations.
Author

Tariq King, CEO and Head of Test IO
Tariq King is a recognized thought-leader in software testing, engineering, DevOps, and AI/ML. He is currently the CEO and Head of Test IO, an EPAM company. Tariq has over fifteen years’ professional experience in the software industry, and has formerly held positions including VP of Product-Services, Chief Scientist, Head of Quality, Quality Engineering Director, Software Engineering Manager, and Principal Architect. He holds Ph.D. and M.S. degrees in Computer Science from Florida International University, and a B.S. in Computer Science from Florida Tech. He has published over 40 research articles in peer-reviewed IEEE and ACM journals, conferences, and workshops, and has written book chapters and technical reports for Springer, O’Reilly, Capgemini, Sogeti, IGI Global, and more. Tariq has been an international keynote speaker and trainer at leading software conferences in industry and academia, and serves on multiple conference boards and program committees.
Outside of work, Tariq is an electric car enthusiast who enjoys playing video games and traveling the world with his wife and kids.
EPAM were Exhibitors in EuroSTAR 2025. Join us at EuroSTAR Conference in Oslo 15-18 June 2026.