If you are reading this article, likely, you’ve already recognized the value of incorporating UI tests for every pull request in your development process. In short, it’s the single way to be confident that your main branch is ready for release anytime. Releasing excellent and stable versions is crucial in the mobile world, where a user fully manages an app update process, unlike the backend world. If you are a newcomer to the topic of UI Tests for Android, please explore my previous article or Alex Bykov’s talk, where you will find all details and explanations.
While beneficial, running UI tests on each PR introduces significant challenges for the underlying Infrastructure. As a result, almost every team that attempts to implement UI tests for each PR encounters difficulties, often making the same mistakes and investing considerable time and resources in the process. In this article, I will delve into the specific requirements of the Infrastructure needed for running UI tests on PRs and discuss the solutions available in the market. By comprehensively understanding the infrastructure challenges and available explanations, development teams can better navigate the complexities of implementing UI tests for each PR, ultimately saving time and resources.
UI Test Infrastructure
First, let’s define the term “UI Test Infrastructure.” “UI Test Infrastructure” is the thing that allows running the UI tests. On each PR. Any number of tests. From a user’s (Software Engineering and QA Teams) perspective, it looks like I send a command to execute a bunch of tests and receive a report. It’s all. It must be simple for those who use it. But it is complex for those who build and support the solution. So, our final goal is to build this Infrastructure somehow using internal or external solutions and resources.
Okay, now let’s refresh our memory about the entire picture of the UI Test process with some updates that appeared last time.
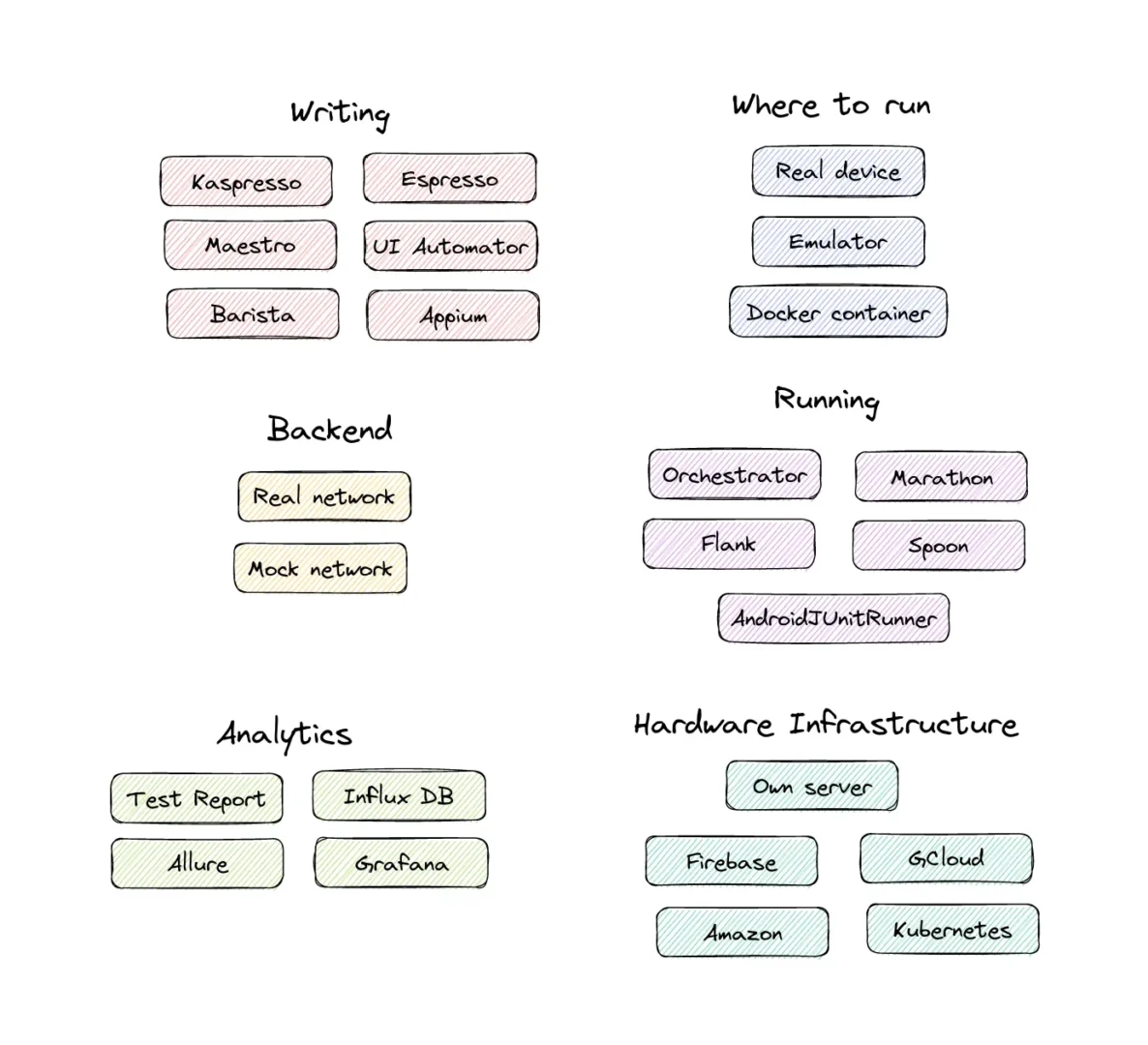
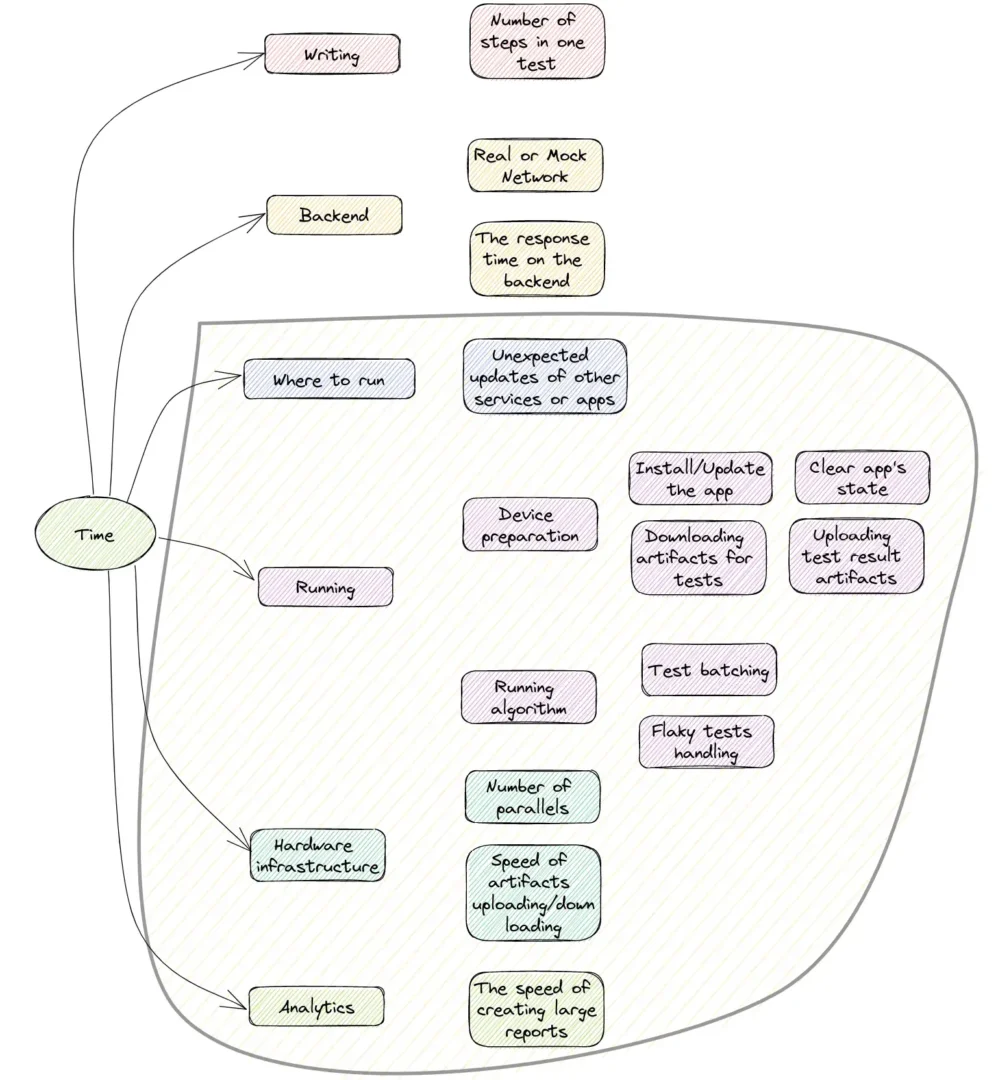
You see a lot of details in the puzzle. Now, have a look at where “UI Test Infrastructure” is presented.
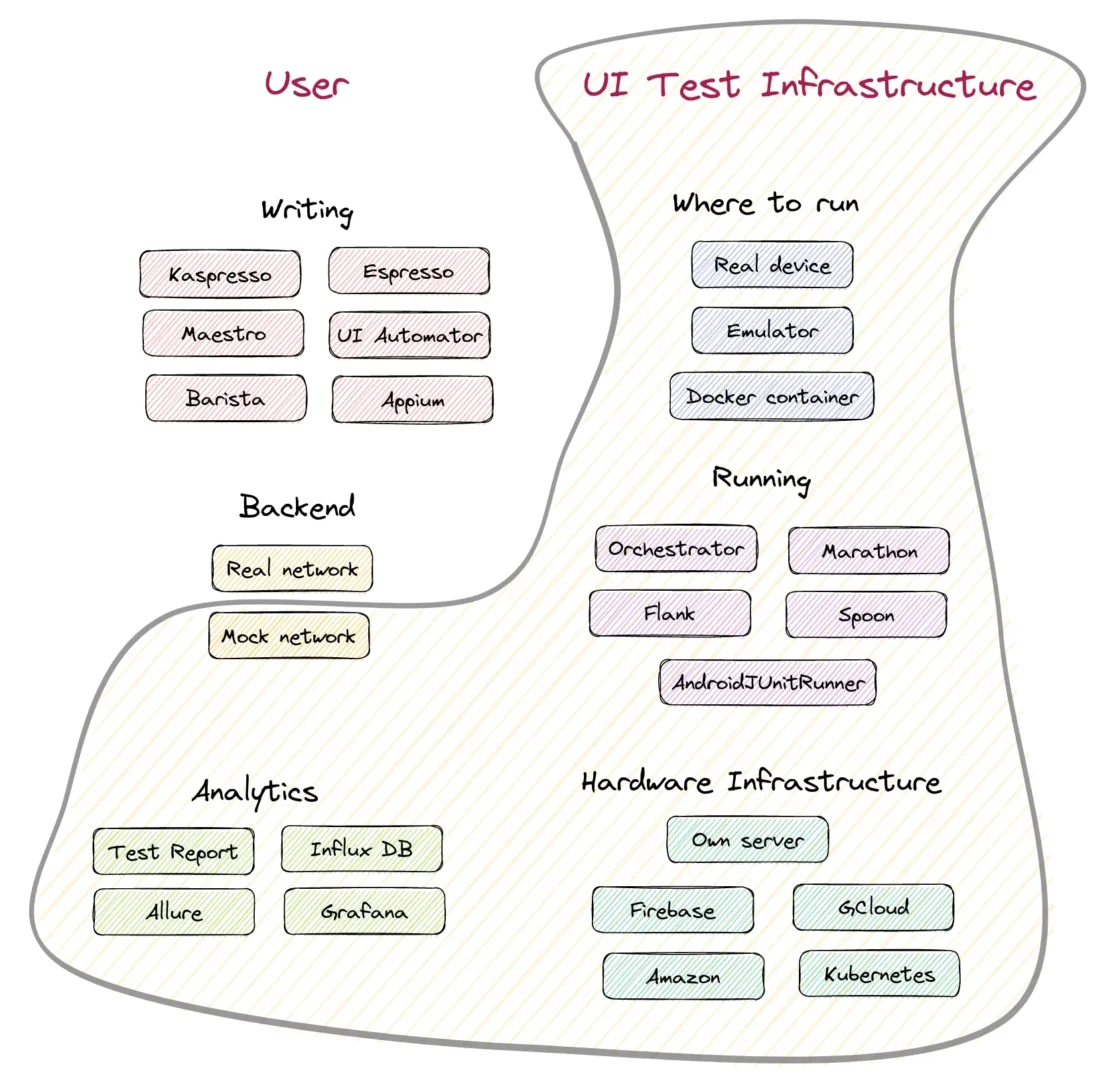
“UI Test Infrastructure” covers an extensive set of various things. Writing and Backend parts stay on the User side because only the user (developer or SDET) can create tests now. Therefore, writing is out of the scope of this article. An excellent comparison of all writing tools is described in the articles Where to write Android UI tests (Part 1) and Where to write Android UI tests (Part 2) (except Maestro, which appeared after publishing). The backend stuff regarding testing against real or mock networks will be partly touched on later. But I need to mention that Mock Network at scale becomes the responsibility of UI Test Infrastructure too.
Requirements
Before delving into the complexities of building this infrastructure, I recommend to begin with a clear set of requirements and expectations. These will serve as a roadmap to guide you through the intricate process of constructing the infrastructure. Also, it is important to remember that the main users of UI Test Infrastructure are developers, SDETs (Software Development Engineers in Test), and QA. As such, our focus should be optimizing their working experience and ensuring a comfortable and efficient environment for these professionals.
Have a look at the image below.
Now, let’s consider point by point.
Supported platforms
In Android development, there are two primary platforms for creating UI tests:
- The native platform, where developers utilize tools exclusively provided by Google, such as Espresso and UI Automator. Solutions like Kaspresso, Barista and etc., are built on top of Espresso and UI Automator.
- Appium, an open-source, cross-platform testing framework.
Interface
Next, a fundamental expectation is the ease of integration with existing CI/CD systems through plugins and the ability to utilize the infrastructure from the command line interface (CLI). The plugin and CLI should offer at least the flexibility to filter tests for execution and select the desired devices.
On top of this basic functionality, different verification modes should be supported, i.e. fast runs vs verifying a fix for flakiness. More details about these terms will be provided later.
Reports
At the end of a run, a user expects to see reports that contain at least the following information:
- the final result: passed or failed
- number of executed, successful, failed and ignored tests
- information about failed tests like stack trace, device logs, and video
- some analytics, like the percentage of failed tests, including retries
Stability
Stability is a comprehensive term encompassing various aspects of UI testing. A test may be unstable (or flaky) due to numerous reasons, such as poorly written tests, an unstable backend or an unreliable network if the test depends on a real backend, feature flags, an improperly set up or unstable device (e.g., a Google service updating or unturned-off animation), framework instability (Espresso, UI Automator, and Appium are known to have their quirks), or internal issues with the test infrastructure caused by factors such as high load or crashes in one of the internal services.
Have a glance at the image below to summarize the possible reasons for failures:
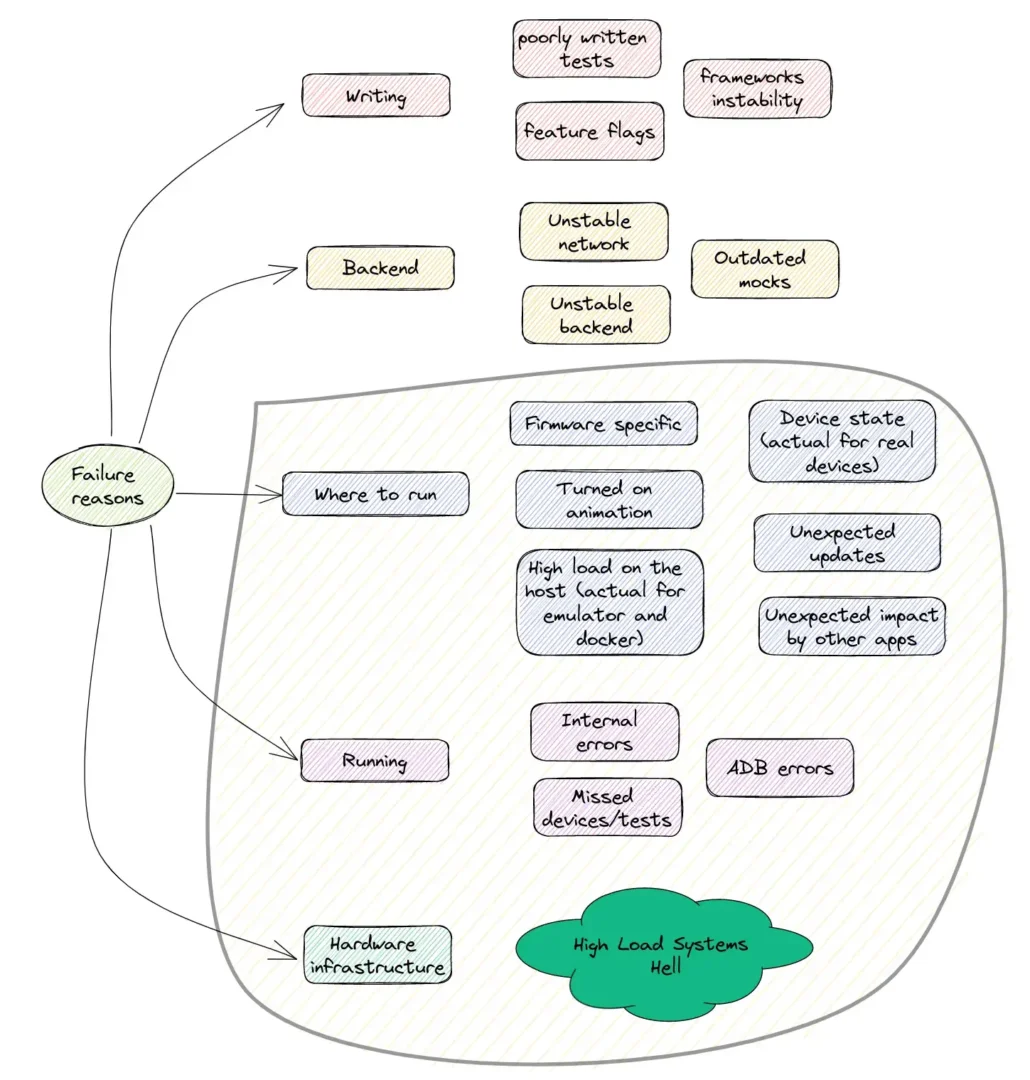
When selecting an infrastructure, we expect full stability or, at the very least, quick recovery that does not impact the overall results and time. The UI Test Infrastructure should cover areas “Where to run”, “Running”, and “Hardware infrastructure”.
Over time, the number of UI tests tends to grow, and with it, the emergence of flaky tests. A flaky test is a test that works most of the time correctly but occasionally fails due to peculiar reasons. Unfortunately, flaky tests are an inescapable reality in UI testing. While it is crucial to investigate the causes, it is not great to block a pull request due to a single occasionally failed UI test. Therefore, as a user of UI test infrastructure, I expect a straightforward and integrated retry mechanism to be available.
Time and Scalability
Test suite execution time is a critical factor for all UI test infrastructures. To better understand this, let’s first examine the elements that influence execution time:
These factors can be divided into two groups: those that depend on the user’s tests and those related to the infrastructure.
Various strategies can be employed to reduce test execution time. One widely-used approach is to focus on specific functionality within a single test by mocking the backend and avoiding repetitive actions such as logging in.
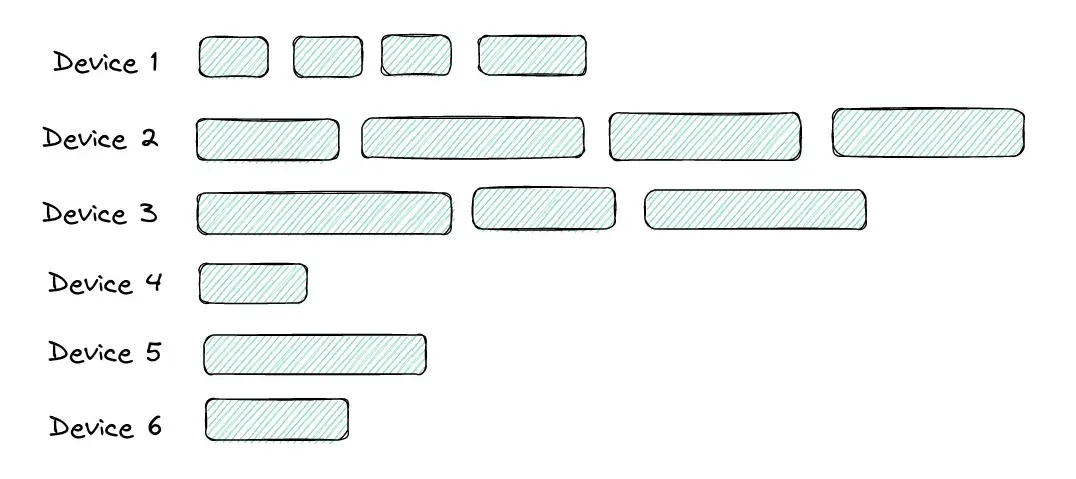
Regarding infrastructure, the test execution algorithm plays a vital role in determining the time required. For instance, consider a test run with a suboptimal batching strategy:
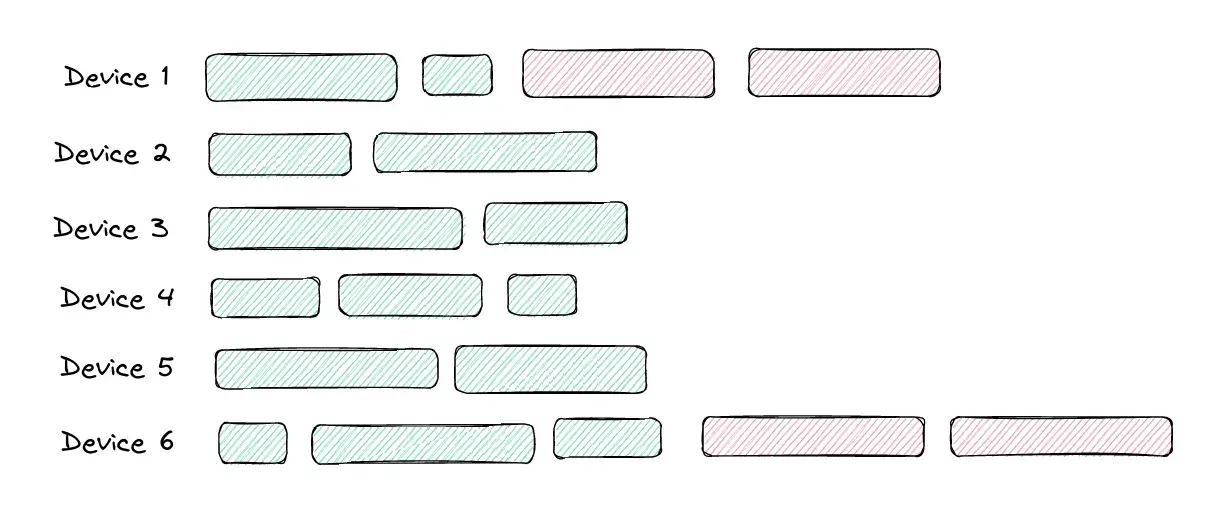
Alternatively, examine a test run with a non-optimal retry policy:
In my recent study, which included over 30 interviews with various development teams, I found that most teams are willing to wait 15 minutes for a UI test run on a pull request. This suggests that even with numerous developers and UI tests, not optimally written tests, concurrent PR runs, or flaky tests, all PRs should be completed within this 15-minute window.
However, it’s a common scenario that PR waiting times can extend from 15 minutes to several hours when the infrastructure is under heavy load, often resulting in rejections due to timeouts. This highlights the importance of optimizing the system to handle such situations efficiently. That’s why I’ve included “Scalability” in the title.
Security
Security protects the test environment, data, and application from unauthorized access, tampering, or malicious activities.
Some critical aspects of security in an Android UI testing infrastructure include:
- Authentication and authorization: Ensure only authorized users can access the testing environment, data, and resources.
- Data protection: Safeguard sensitive information, including test data and user credentials, using encryption in transit and at rest. Implement proper data storage and disposal practices to prevent data leaks.
- Network security: Secure the communication between testing devices, servers, and other infrastructure components.
Cost
I would emphasize the two main aspects:
- The price model and utilization of paid resources. Generally, there are the following price models: pay for a parallel and pay for a minute. However, choosing and using the appropriate price model wisely is a separate big topic.
- The second aspect is the internal UI Test Infrastructure algorithms and solutions that allow spending less money running the same test suite. One of the possible optimizations is described above (better batching and handling of flaky tests).
You can find more details about cost price models and specific examples in the article titled “I Want to Run Any Number of Android UI Tests on Each PR: Cost, Part II.”
Support
Last on this list, but certainly not least in terms of importance, is Support. Many teams prioritize not just the service itself but also the quality of support provided. Factors such as prompt responses, a willingness to help, and the ability to save time for the team are highly valued. Additionally, prioritizing features based on client needs and preferences further enhances the overall support experience. Open-sourcing portions of Infrastructure is often highly appreciated by clients, as it fosters trust in the solutions provided and enables them to better understand the underlying mechanics.
Available Cloud Solutions on the market
As an engineer, you have the option to create your own infrastructure that meets all of the above requirements. However, it’s clear that this task can be challenging and complex. Therefore, let’s explore cloud solutions that offer ready-made options.
There are the following Cloud solutions:
- Marathon Cloud
- Firebase Test Lab
- BrowserStack
- emulator.wtf
- SauceLabs
- AWS Device Farm
- Perfecto Mobile
- LambdaTest
Please review the articles below, where I have thoroughly examined each solution based on the aforementioned requirements.
- I want to run any number of Android UI tests on each PR. Existing solutions (BrowserStack, Firebase Test Lab). Part III
- I want to run any number of Android UI tests on each PR. Existing solutions (SauceLabs, AWS Device Farm, LambdaTest, Perfecto Mobile). Part IV
- I want to run any number of Android UI tests on each PR. Existing solutions. Part V
Conclusion
In this article, I examined the concept of UI Test Infrastructure and described the essential criteria for selecting or constructing it. As you might have observed, developing an Infrastructure that fulfills all of the aforementioned requirements and addresses potential issues can be quite complex and challenging. Therefore, I emphasized the existing Cloud Solutions that provide ready-made alternatives.
Author

Prashant Mohan
Evgenii Matsiuk, co-founder at MarathonLabs, co-author of Kaspresso, Android Google Developer Expert.
Testwise were exhibitors in EuroSTAR 2025. Join us at EuroSTAR Conference in Oslo 15-18 June 2026.