AI-accelerated development has fundamentally changed how software is built, and across the industry, its impact on quality is already measurable. In SmartBear’s Closing the AI software quality gap study, we found nearly 70% of software professionals report application quality is declining as AI speeds up code generation, with development velocity increasingly outpacing teams’ ability to test effectively.
This is not a future risk or a theoretical concern. The gap between code generation speed and testing capacity continues to widen, creating an unsustainable dynamic. Teams face an impossible choice: either bottleneck development to maintain testing rigor or accept degraded application quality as development races ahead unchecked. But what if that tradeoff isn’t actually necessary?
Application integrity: The new standard for AI-era quality
Application integrity is the continuous, measurable assurance that your software works as intended at AI speed and scale. When code generation wildly outpaces application validation, maintaining integrity becomes impossible without sacrificing the velocity gains that AI-accelerated development promises. The consequences of compromised application integrity are severe: regulatory fines, brand damage, customer loss, and revenue impact. SmartBear addresses this challenge with the SmartBear Application Integrity Core™ – unifying the system of record (API catalog and test repository) with MCP tools and agentic workflows that empower developers and AI agents to deliver software that just works. Whether testing runs in cloud-native environments, on-premises infrastructure, or is managed directly within Jira, teams can continuously validate applications while maintaining control over quality as development accelerates.
SmartBear’s testing portfolio: Built for AI velocity
BearQ™: Autonomous QA for the next generation
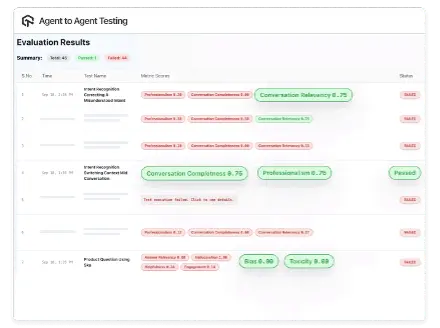
SmartBear BearQ represents a fundamental shift in how testing keeps pace with AI-accelerated development. This agentic QA system operates at the highest levels of autonomy, serving as an exploration and testing analog to autonomous coding tools. BearQ thinks and tests like a real user, exploring applications autonomously and discovering flows rather than following pre-determined scripts. It adapts continuously as applications evolve, automatically updating tests without manual rewrites while maintaining full human visibility and control.
Reflect: Vision-based AI automation for modern applications
Reflect is a cloud-native test automation platform that uses vision-based AI to create and maintain tests that remain stable as applications evolve. By interpreting the UI the way users do, Reflect removes dependency on brittle selectors, enabling automation across web, mobile, and API workflows within a single platform. Teams can generate tests agentically or through natural language prompts, with built-in self-healing that automatically adapts to UI changes, reducing maintenance overhead while expanding coverage.
TestComplete: Enterprise desktop and web UI automation
TestComplete provides deep automation support for complex desktop applications, internal web systems, and legacy frameworks that modern cloud-first tools cannot reliably support. Its ability to run in secure, on-premises environments makes it essential for organizations with compliance requirements or specialized UI frameworks. Supporting multiple automation approaches – from record-and-replay to full scripting – TestComplete enables teams with different skill levels to work within the same system. Advanced hybrid object recognition combines property-based detection, text extraction, and vision AI to interact accurately with complex interfaces.
QMetry: Enterprise testing platform for scalable QA
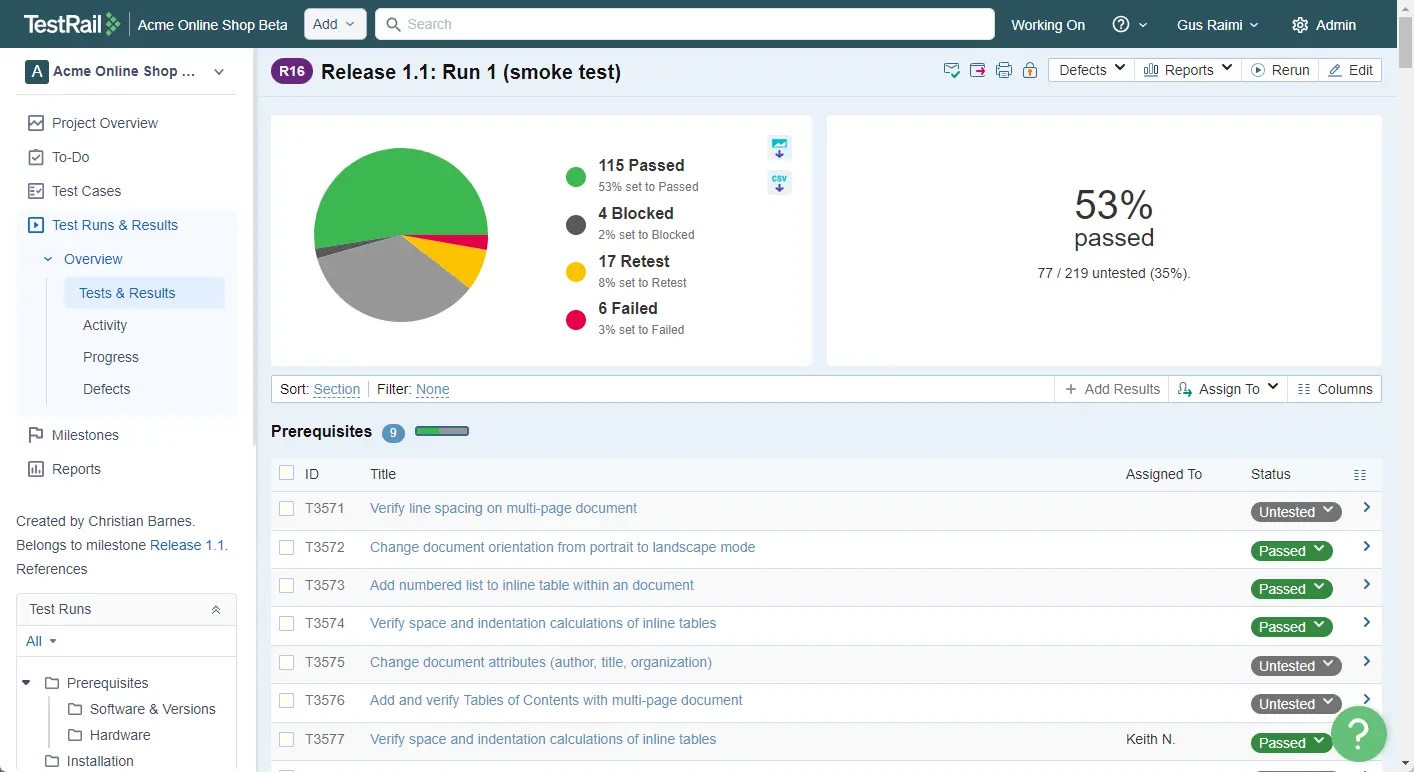
QMetry is an enterprise test management platform that unifies performance, visibility, and automation in a single system designed to handle millions of test cases without performance degradation. As a centralized testing system of record, QMetry provides real-time visibility, audit-ready traceability, and customizable reporting across the entire organization. AI-driven capabilities streamline test creation and maintenance, with automated test case generation reducing creation time from 30-60 minutes to under 60 seconds. Built-in compliance features support regulated environments with flexible deployment options.
Zephyr: Jira-native testing for agile teams
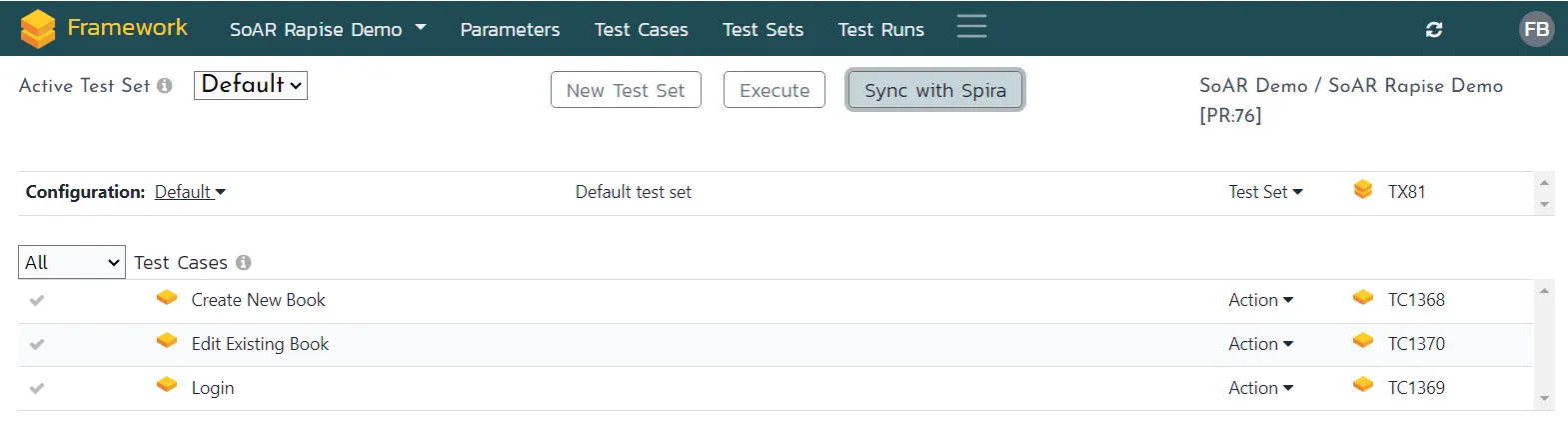
Zephyr integrates testing directly within Atlassian Jira workflows, enabling teams to create, execute, and track tests alongside user stories, requirements, and defects without switching tools. This Jira-native approach provides end-to-end traceability across planning, execution, and validation while maintaining performance even as test libraries grow. Rovo agent skills enable natural-language queries to evaluate test coverage and assess release readiness, while MCP server capabilities extend Zephyr beyond Jira for more flexible workflows.
Swagger: Spec-driven API testing and contract validation
Swagger enables teams to design, test, document, and govern APIs using OpenAPI as a shared source of truth. By deriving testing directly from API specifications, Swagger reduces drift between design and implementation while enabling both functional validation and contract testing. Swagger Functional Testing validates endpoints against OpenAPI specifications, ensuring requests, responses, and data structures conform to defined contracts. Swagger Contract Testing verifies that API changes don’t break downstream consumers, critical for distributed and microservices-based architectures.
ReadyAPI: Comprehensive API testing for real-world conditions
ReadyAPI enables teams to validate API behavior across functional and performance scenarios while simulating dependencies through service virtualization. Supporting REST, SOAP, GraphQL, JMS, and other protocols, this on-premises platform allows functional tests to be converted into load tests without rebuilding scenarios. LLM-driven test generation creates and validates complex test cases with large data volumes using no-code, prompt-based workflows. Service virtualization simulates dependent systems, enabling testing when external services are unavailable – especially valuable in complex environments requiring infrastructure control.
A testing system that scales with modern development
The SmartBear testing portfolio addresses the fundamental challenge facing development teams: maintaining application integrity as AI accelerates code generation. Individual tools solve specific testing challenges across UI automation, API validation, and test orchestration. Together, they create a unified testing system that scales with AI-driven development velocity.
When testing infrastructure operates as a coordinated system rather than isolated tools, teams gain the ability to validate applications comprehensively without sacrificing speed. Automation scales without becoming fragile. API changes are validated before reaching consumers. Testing coverage remains aligned with development rather than trailing behind it. The result is not a choice between speed and quality – it’s the ability to deliver both while maintaining the application integrity that modern software demands.
Author

Rob McNeil Senior Manager of Product Marketing
Rob is a Senior Manager of Product Marketing focused on defining the go-to-market strategy for SmartBear’s portfolio of software testing products. He is passionate about engaging with customers and bringing their voices into product strategy so that feature launches align with real market needs. He has been with SmartBear for four years, with his more recent projects centered on researching the impact of AI, including how it is bringing significant changes to software developers and testers, and launching new generative AI and agentic AI features to meet the demands of the evolving development landscape.
SmartBear are Gold Sponsors in EuroSTAR 2026. Join us at EuroSTAR Conference in Oslo 15-18 June 2026.