When we look at the history of software engineering and quality engineering (QE), we often see significant shifts occurring every decade or so. Each has brought with it new tools, processes and methodologies that have improved the way we develop, test, and maintain software applications, and by extension, the experiences we deliver to end users.
Test automation emerged in the 1970s to accommodate growing business demands, with Agile methodologies following in the ’90s to enhance quality and security. From the 2000s, DevOps and low-code strategies enabled quicker deployment and talent attraction.
The software industry was further propelled by social, mobile, analytics, and cloud (SMAC) technologies, completely transforming it as we knew it.
Despite these advancements, challenges persist in delivering quality products at speed, managing cybersecurity risks, containing costs, reducing technical debt, and sourcing skilled talent.
Now, with the emergence of generative AI, we stand on the brink of the next major evolutionary leap in software and quality engineering. This technology merges with traditional engineering principles to significantly expedite development, testing, and maintenance processes—ensuring faster market delivery of innovative products while freeing up time for strategic initiatives.
Introducing the Gen AI Amplifier for Software and Quality Engineering: Quality Reimagined.
Accelerate QE with the Gen AI Amplifier
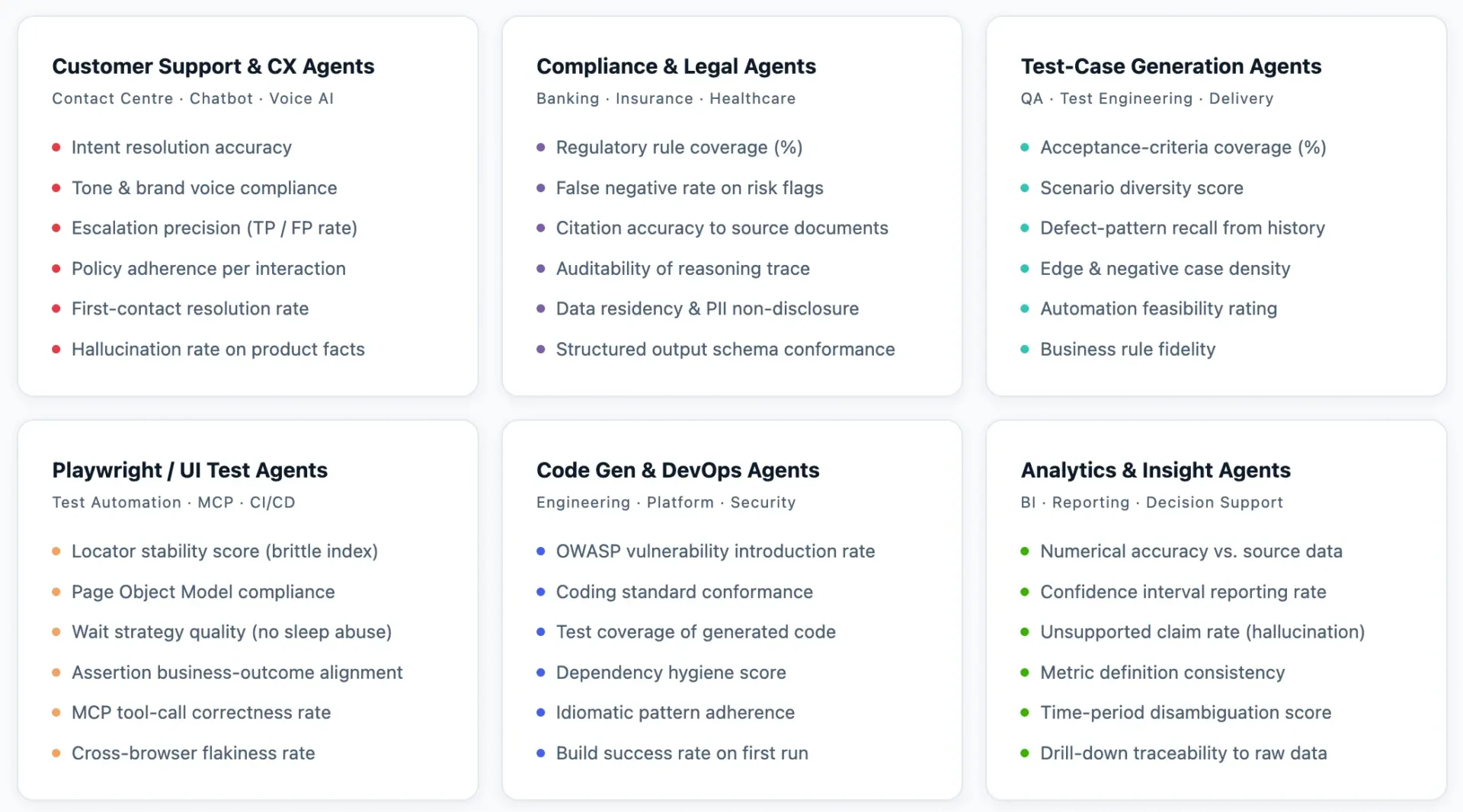
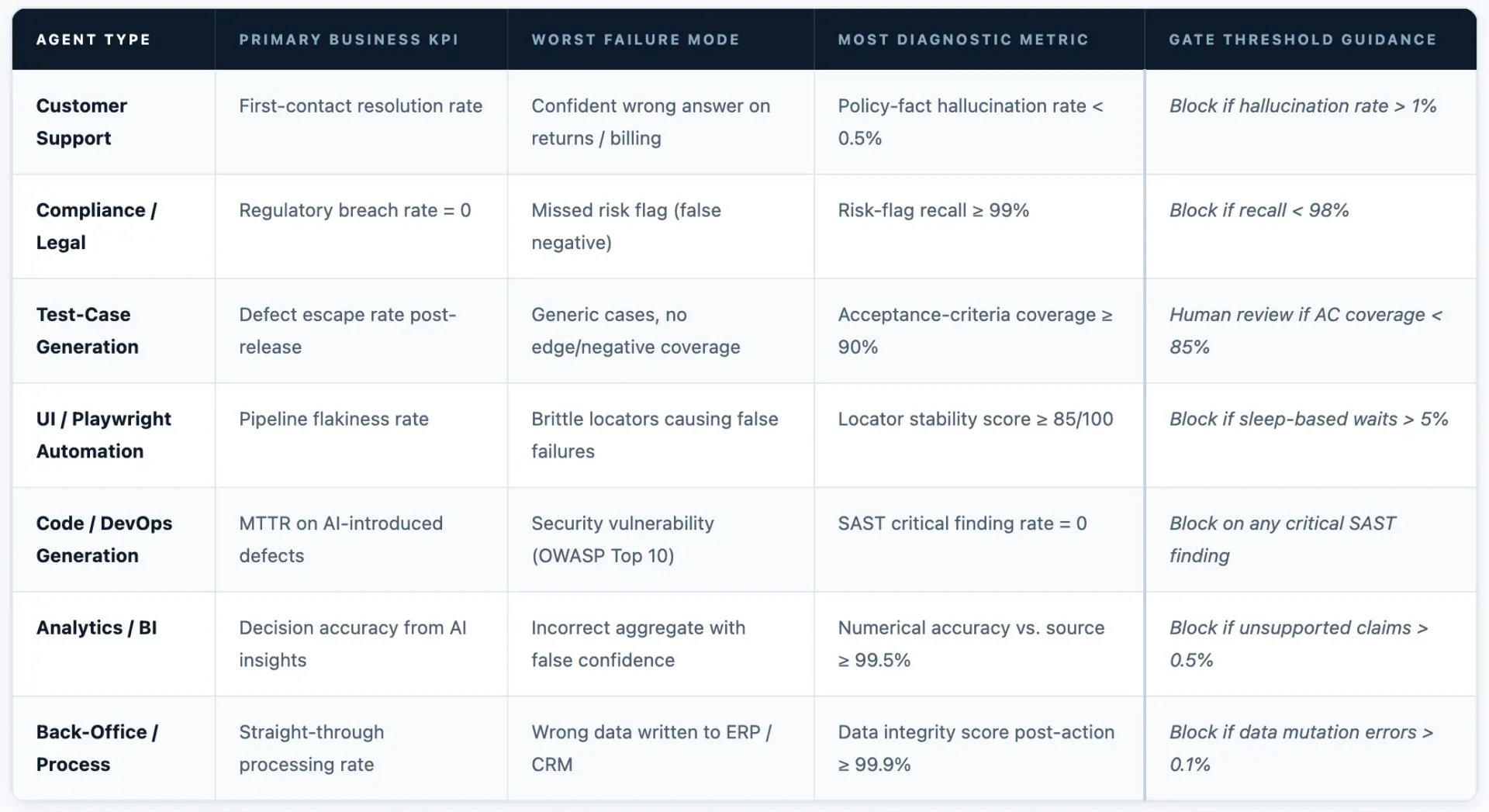
The Gen AI Amplifier for Software and Quality Engineering is a groundbreaking accelerator designed to optimize the Quality Engineering & Testing (QE&T) stages of the software development life-cycle (SDLC). By applying the powerful capabilities of generative AI to our industry-leading best practices, frameworks, and methodologies, we’ve crafted a uniquely amplified approach.
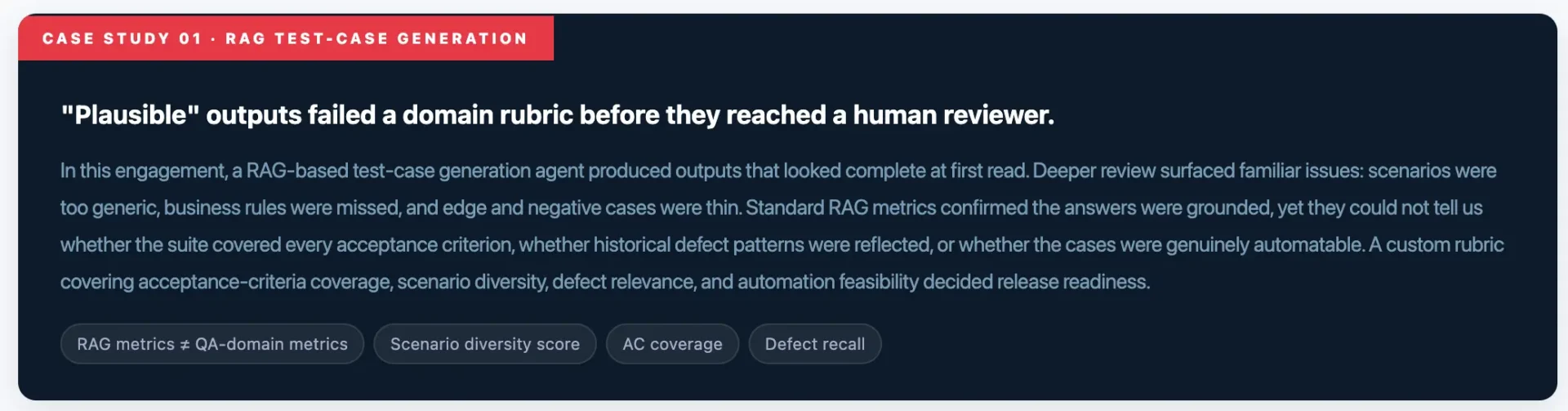
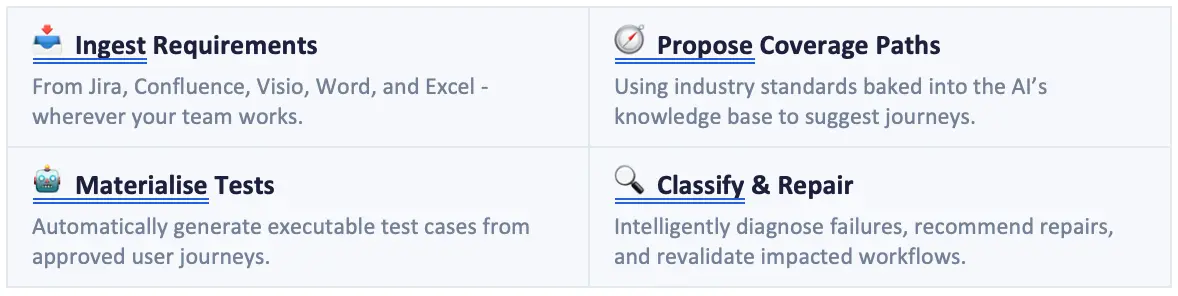
This accelerator is tailored to enhance the efficiency of QE&T tasks across the entire software life-cycle, from planning and design to building, testing, and deployment. It incorporates pre-built use cases and AI-driven prompts for every life-cycle stage—ranging from requirements and user stories to architecture modeling, design, code transformation and test case generation, API testing, synthetic test data and test automation.
The Gen AI Amplifier is built on a robust QE foundation using our proprietary assets, and thoroughly tested and validated to ensure consistent, reliable results. It is integrated with multiple LLMs within a secure architecture framework, which is further strengthened by our gen AI guardrails, knowledge framework, and data platforms.
The Gen AI Amplifier is helping us do in minutes and hours what software development and QA teams have traditionally needed days or weeks for:
- Generating first requirements from conversation documents
- Generating TMAP-guided test cases from requirements
- Generating comprehensive test data
- Generating automated test scripts, and more.
Generative AI adoption is driving impact across the entire test ecosystem
In the 15th World Quality Report, we learned that out of the 1,750+ senior executives surveyed globally, 64% have identified processes or applications that can benefit from AI. The majority are using AI towards building and improving test scope along with improving performance engineering, as well as the test ecosystem overall. They are actively utilizing AI to optimize their testing processes. 79% of the quality leaders agree that AI systems are going to be used to help them optimize their test scope and increase velocity.
64% of organizations have identified processes/ applications that can benefit from AI.
79% of quality leaders agree that AI systems are going to be used to help them optimize their test scope and increase velocity.
(Data from World Quality Report, 15th Edition, 2023-24)
The Gen AI Amplifier supports the full life-cycle for agile teams. We’ve integrated multiple Gen AI models in a secure environment, with pre- engineered and tested prompts built with our industry-leading quality engineering methodology, agile framework, and cloud-native architectural best practices.
With the help of our AI experts at Sogeti, the Gen AI Amplifier augments business analysts, product owners, lead architects and quality engineers at every stage – from requirements gathering and infrastructure design to comprehensive software testing.
Quality amplified early on, and at every stage, yields a significantly increased level of productivity, efficiency, and acceleration.
Closing thoughts, for now
Diving into generative AI is really exciting, and I believe in the importance of remaining grounded and focused on pragmatic experimentation. This isn’t just about incremental improvements—it’s about redefining our approach to software engineering and QA. While our ultimate goals haven’t changed, our means to achieve them have evolved. Let’s explore generative AI’s potential responsibly, learning and adapting as we go. Together, we’ll discover how these advanced tools can enhance our industry without losing sight of our core objectives.
Watch this space as we unveil more about the Gen AI Amplifier and its impact on software QA.
Author

Antoine Aymer
CTO for Quality Engineering & Testing, Sogeti
Sogeti are Exhibitors in EuroSTAR 2026. Join us at EuroSTAR Conference in Oslo 15-18 June 2026.