Ever wonder how conference submissions are reviewed or how the overall review process works? Well we can tell you that the EuroSTAR Conference Programme is the culmination of a community wide collaboration.
Led and crafted by the EuroSTAR Committee, who first call for submissions in line with a theme chosen by the Programme Chair. In 2021, this is Fran O’Hara. Testers far and wide then submit their suggested talks. Each year, there are hundreds of submissions to be reviewed, and, in order to create a balanced and varied programme, each submission is reviewed by up to 5 people (anonymously i.e. talk details viewed, not the submitters’ name).
This is where the community get involved and each year, the EuroSTAR team welcome reviewers from the testing community. Some are past speakers, some have been involved with shaping EuroSTAR since the beginning and all are valued members of the EuroSTAR family.
This is time intensive and we are very grateful to each of our reviewers for their time and dedication. Following the community review, the Programme Committee will then come together to start crafting this year’s programme of talks.
This blog is a behind the scenes introduction to a first time reviewers experience, written by Sérgio Freire of Xray, and details how he approached his reviews.
EuroSTAR Behind the Scenes – Sérgio’s Experience
I was invited to review some submissions for EuroSTAR 2021 testing conference. I had never done it before, and even if time is scarce I understand that this is important for many who submit during the Call For Speakers; it’s also a learning experience for me. But how have I tackled this task? How can I make sure I’m fair enough to everyone? Can I test my review process somehow? This is the story of how I tested my review process. Let’s check it out.
Background
Before starting, it’s important to understand the conference context. EuroSTAR 2021 theme is “Engage”. Engagement is a broad topic. It’s about involvement, commitment, challenging, seeking understanding. We deep dive problems and challenges, we embrace them and we overcome them, no matter if they live within us or in our teams. Engaging is, in my perspective, about giving a step forward.
Infrastructure and supporting assets
The review was done using an online tool where we can easily jump between submissions. The tool itself has an interesting and scary bug that may mislead you to think that your already reviewed submissions/scores are lost… however, I found out that it is just a UI glitch 🙂 a forced browser refresh solved the issue.
To assist me as a reviewer, I had scoring instructions that I read before starting reviewing the submissions. These instructions were always open in one of my screens.
Criteria
There were 5 main criteria for me to score:
- engaging
- new ideas
- scope
- relevant to theme
- overall feeling
I felt a bit of doubts on “engaging” vs “relevant to theme”, as the theme is “engaging” and thus some overlap exists. I used the scoring instructions several times, to decide how to score each one of them. Nevertheless, I would prefer a more clear separation between them as they’re not independent variables. The “scope” criterion also left me some doubts, as we’ll see ahead. Finally, there was an open text field “comments” where we could leave a qualitative assessment.
How I did it?
Day 1
I had a setup a quiet room (i.e. my office), so I could read and think carefully. I went over each one of the submissions and scored them; I skipped the “comments” section on purpose so I could not loose much time with them in the first iteration but also to try avoid a bit of bias. Whenever scoring, I regularly looked the scoring instructions if some criteria was not clear to me. I noticed that I was probably assigning “scope” not the meaning it should, as the scoring values were almost identical. Even so, I decided to look at it more carefully on a second iteration. Besides leaving the scores on the online tool, I also took notes in a spreadsheet; thus, I would have a backup 🙂 and I could use it for analysis.
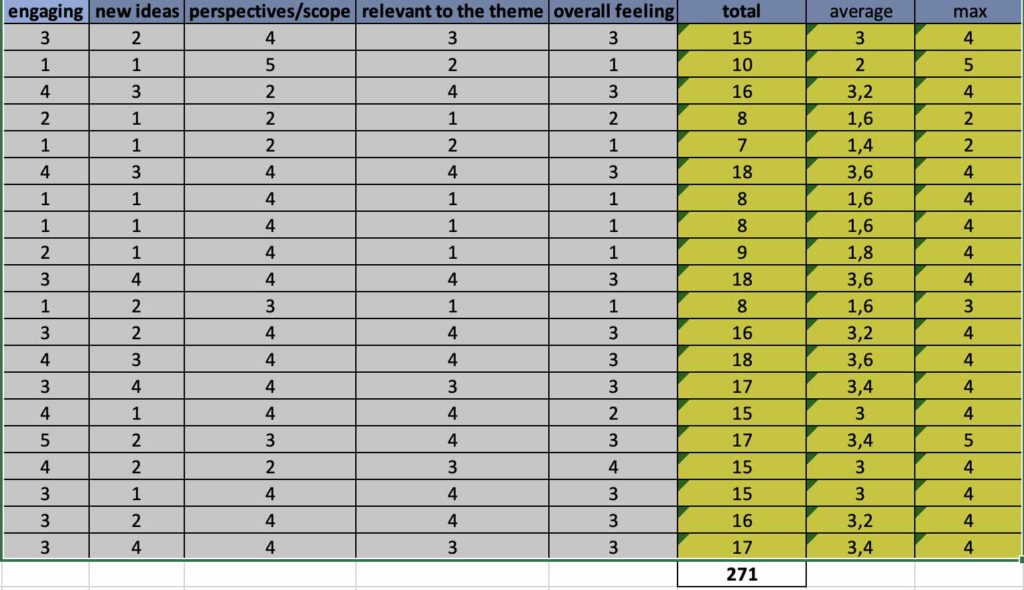
After scoring all submissions, I decided to go over the submissions once again to leave qualitative comments, that I structured in these bullets:
- First impressions: Mostly based on the title and takeaways.
- Takeaways & The Day After: Is it clear what to learn in the end of this session?
- Final assessment: My overall feeling, i.e. a brief summary.
- Would I attend: A yes or no, or eventually a perhaps.
- Cliffhanger/invite to discover: Was there any mystery left? Any invite to learn something intesting during the session?
- Suitable for: beginner, intermediate, advanced.
I was curious to understand if I had some bias that would be reflected more towards time. Thus, I traced a chart with the average scored and a trend line. The result was not shocking. I also made a column with the max score I add assigned in a specific criterion… and I didn’t see any relevant change with time.
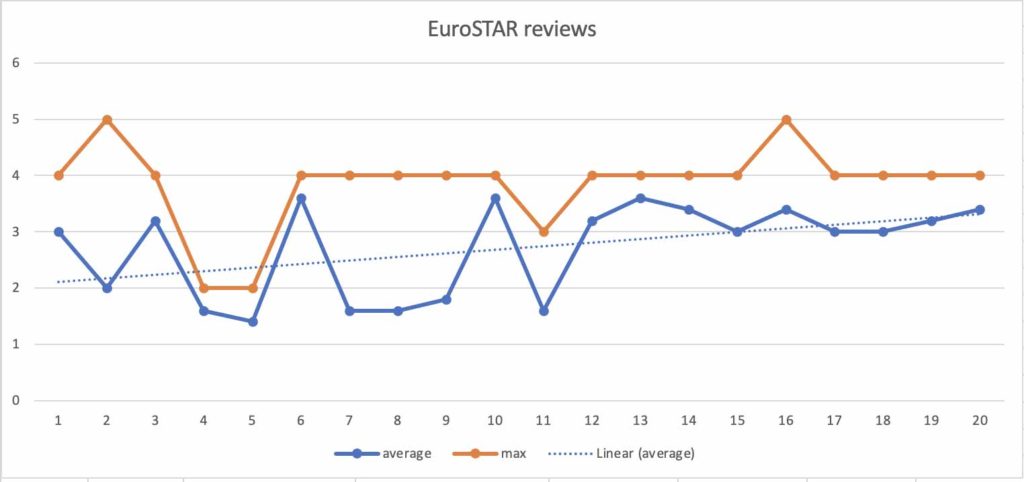
I slept over and I was curious to see what would happen whenever I iterated on this.
Day 2
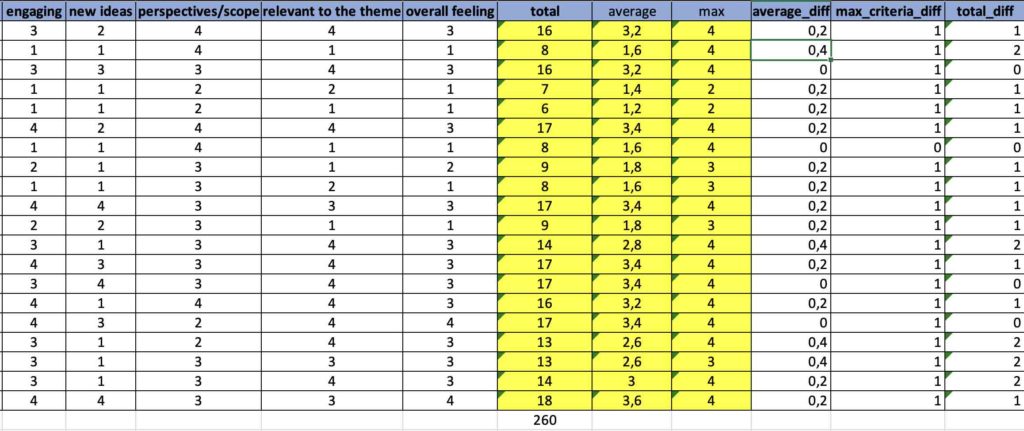
I went over the submissions once again, but in reversed order. Why? To avoid some possible bias related with time and exhaustion.
In terms of criteria, I also did a subtle change. While in the first day I considered “scope” as the criterion for being adequate for the time slot, in the second day I considered more the message clarity because it would be a factor that would help the fit for the available time slot.
Even though overall scoring is a bit lower, the results are not very different from the 1st iteration, where the chart shows also a similar trend line.
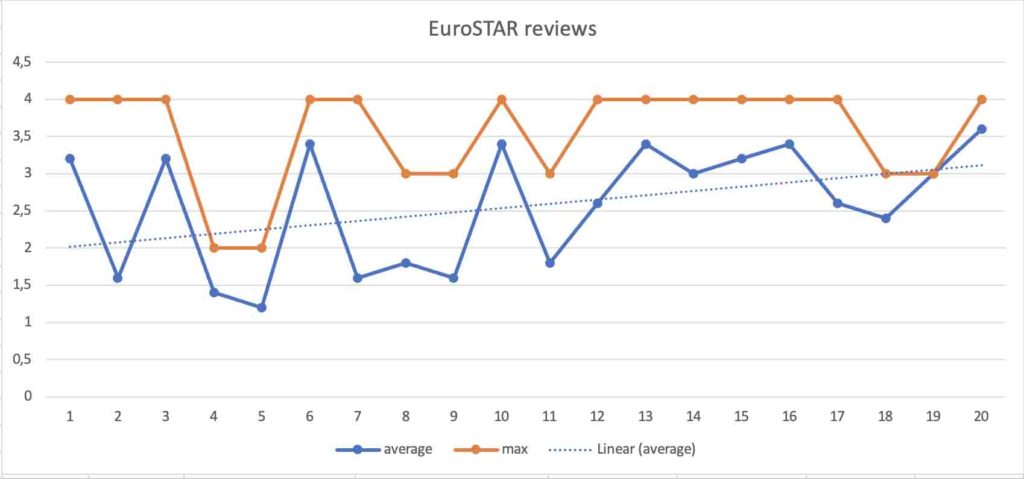
In the spreadsheet, I calculated the absolute difference on the average and on the total score.
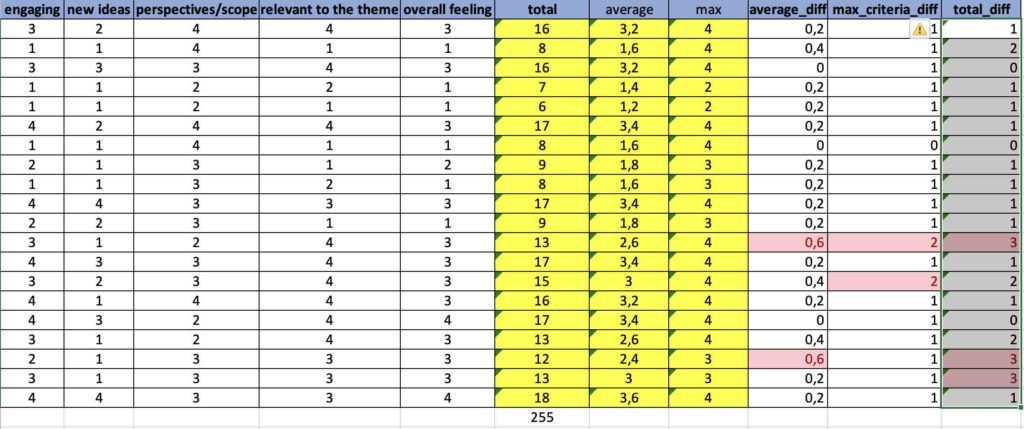
I flagged in red suspicious cases, that would affect my confidence:
- absolute average scoring difference >= 0.5
- absolute difference in individual scores > 1
- absolute total scoring difference > 2
Gladly, only a few reviews appear that I need to have a look at once again. After going over them (i.e. scoring) in this localized 3rd iteration, I seem to be in my confidence interval except for one submission that remains flagged. Why? Well, because in the total score it had 3 points of difference. I read that submission all over and scored it once again. In the end, it was once again in my confidence interval.
Remember the “Comments” section? Well, I decided to go over it and look at “would I attend” bullet and compare it with the “overall feeling” criterion, that implictly should have that reflected. I notice that my decision to attend was correlated with the “overall feeling” criterion but it was not a consequence of it.
Conclusions and final thoughts
On the review process
I had quite a few doubts at start, especially this one: am I going to be fair? But also, I had doubts about how I would perform in this task, my biases, etc.
After looking at the results, my first iteration was trustworthy. I scored the submissions a bit lower during the second day, when I performed the 2nd, 3rd and 4th iterations. However, my first iteration was balanced and scores should reflect that.
I don’t assign 5 or 0 easily. I need to be quite impressed or reject something completely, which for me was not the case.
Scoring talks can be relatively fast but if you want to implement a process such as this one or your own, you’ll spend a lot more time. Even if you don’t, if you consider all the points that can affect a single criterion then it will consume more time indeed.
This whole process of revieweing submissions is also a discovery process about how each one of us works and is able of handling tasks. What works for someone, may not work for someone else.
On submitting a talk
Talks touch us in subtle different ways, so we value them differently. It makes sense, from a quality perspective: we assign value accordingly with our own definition of quality.
There are some generic rules that apply though in most cases and questions that you can think of:
- Having a clear message, not that long not that short is crucial; if we get lost, we tend do discard it rightaway.
- Why should we attend? What can we expect from it?
- How will that talk help the attendee?
- How does that talk align with conference?
- Is it presenting something new, or your own learnings and challenges?
I’ve done a few submissions on the past and I have been unlucky most times. Yes, true. Therefore, I still have much to learn in this matter. I remember when I did a scientific submission for a Usenix conference few years ago, and even though it was a different audience, I had to iterate on the paper a couple of times before it was accepted and I was invited to present. Therefore, as everything, we need to iterate and learn.
Going over this review process, being on the other side of the fence, made even more clear some points mentioned above. By understanding the challenges a reviewer faces, when looking at dozens of submissions, I am a bit more aware of the things I need to have in mind for any submissions I may perform in the future.
It was an interesting thing to do and I’ve learned a bit more on the overall process of submitting (and reviewing) talks for testing conferences. I also appreciate the effort reviewers and program committees have to make, no matter what conference we’re talking about, because this is a process that requires considerable effort if you want to do it right and make it fair.
Note: the 2021 EuroSTAR Conference is taking place 28-30 September this year instead of November and the programme is usually launched at the end of April.
RECEIVE EUROSTAR PROGRAMME NEWS
 Sérgio Freire – Xpand IT – Portugal
Sérgio Freire – Xpand IT – Portugal
Sérgio Freire is a solution architect and testing advocate, working closely with many teams worldwide from distinct yet highly demanding sectors (Automotive, Health, and Telco among others) to help them achieve great, high-quality, testable products. By understanding how organizations work, their needs, context and background, processes and quality can be improved, while development and testing can “merge” towards a common goal: provide the best product that stakeholders need.
Sérgio spoke at EuroSTAR 2020 and you can check out his personal blog at www.sergiofreire.com