
Experiences with Test Gap Analysis in Practice
Thanks to CQSE for providing us with this blog post.
Most errors occur in code that has been changed lately (e.g., since the last release of a software system) [1,2]. This is of little surprise to practitioners, but how do we ensure that our tests cover all such changes, in order to catch as many of these defects as possible?
Do Tests Cover Code Changes in Practice?
In order to better understand to which degree tests actually cover changes made to a software system, we tracked development and testing activity on an enterprise information system, comprising of about 340k lines of C# code, over a period of 14 months, corresponding to two consecutive releases [1].
Through static code analysis, we determined that for each of these releases, about 15% of the source code were either newly developed or changed. Using a profiler, we recorded the code coverage of all testing activities, including both automated and manual tests. This data showed that approximately half of the changes went into production untested – despite a systematically planned and executed testing process.
To quantify the consequences of untested changes for users of the software, we then reviewed all errors reported in the months following the releases and traced them back to their root causes in the code. We found that changed, untested code contains five times more errors than unchanged code (and also more errors than changed and tested code).
This illustrates that, in practice, untested changes very frequently reach production and that they cause the majority of field errors. We may, thus, systematically improve test quality, if we manage to test changes more reliably.
Why Do Changes Escape Testing?
The amount of untested production code we found in our study actually surprised us, when we originally conducted this study. Therefore, we wanted to understand why this many changes escape testing.
We found that the cause of these untested changes is – to the contrary of what you may assume – not a lack of discipline or commitment on the testers’ part, but rather the fact that it is extremely hard to reliably identify changed code manually, when testing large systems.
Testers often rely on the description of individual issues from their issue tracker (e.g., from Jira or Azure DevOps Boards), in order to decide whether some change has been sufficiently tested. This works well for changes made for functional reasons, because the issues describe how the functionality is supposed to change and it is relatively easy to see which functionality a test covers.
However, there are two reasons why issue trackers are not suitable sources of information in consistently finding changes:
- First, many changes are technically motivated, for example, clean-up operations or adaptations to new versions of libraries or interfaces to external systems. Respective issue descriptions do not clarify which functional test cases make use of the resulting changes.
- Second, and more importantly, the issue tracker often simply does not document all important changes, be it because someone forgot or did not find the time to update the issue description or because someone made changes they were not supposed to make, e.g., due to a policy that is currently in place.
Thus, we need a more reliable source to determine what has been changed. Only then, we can reason about whether these changes have been sufficiently tested.
Test Gap Analysis to the Rescue!
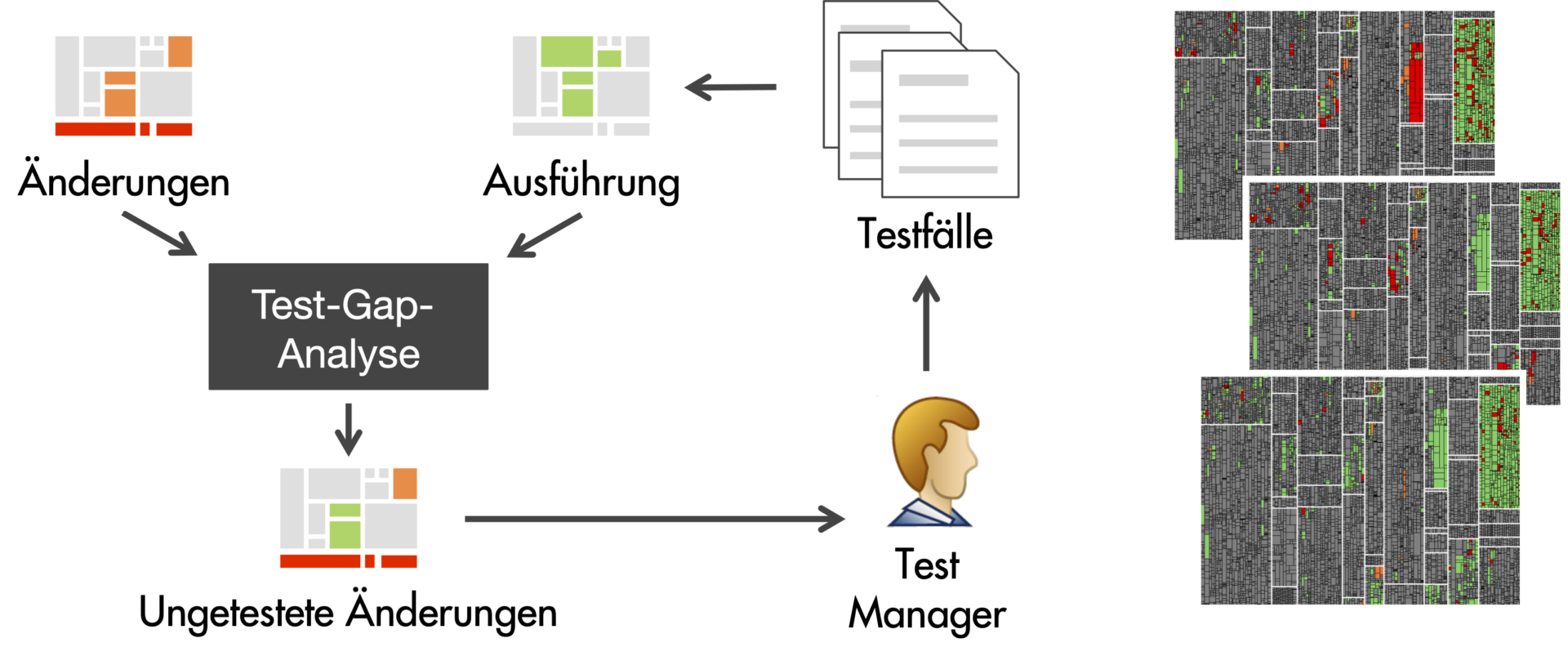
Test Gap Analysis is an approach that combines static analysis and dynamic analysis to identify changed-but-untested code.
First, static code analysis compares the current state of the source code of the System under Test to that of the previous release in order to determine new and changed code areas. In doing so, the analysis filters out refactorings, which do not modify the behavior of the source code (e.g., changes to documentation, renaming of methods or moving of code) and, thus, cannot cause new errors. The remaining code changes lead to a change in the behavior of the system.
For the enterprise information system from before, all changes for one of the releases we analyzed are depicted on the following tree map. Each rectangle represents a method in the source code and the size of the rectangle corresponds to the method’s length in lines of source code. We distinguish unchanged methods (gray), from new methods (red) and modified methods (orange).

Second, dynamic analysis captures code coverage (usually through a coverage profiler). The crucial factor here is that all tests are recorded, across all test stages and regardless of whether they are automated or manually executed.
We use the same tree map as above, to visualize the aggregated code coverage at the end of the test phase. This time, we distinguish between methods that were executed by at least one test (green) and methods that were not (gray).

Third, Test Gap Analysis detects untested changes by combining the results of the static and dynamic analyses. Again, we use our tree map to visualize the results, distinguishing methods that remain unchanged (gray) from changed-and-tested methods (green), untested new methods (red) and untested changed methods (orange).

It is plain to see that whole components containing new or changed code were not executed by even a single test in the testing process. No errors contained in this area can have been found in the tests!
Using Test Gap Analysis
Test Gap Analysis is useful when executed regularly, for example, every night, to gain insights each morning into the executed tests and changes made up until the previous evening. Each day, an updated Test Gap treemap, e.g., on a dashboard, then helps test managers decide whether further test cases are necessary to run through the remaining untested changes. This creates an ongoing feedback loop to steer the testing efforts and make informed decisions.
Which Projects Benefit from Test Gap Analysis?
We have used Test Gap Analysis on a wide range of different projects: from enterprise information systems to embedded software, from C/C++ to Java, C#, Python and even SAP ABAP. Factors that affect the complexity of the introduction are, among others:
- Execution environment. Virtual machines (e.g., Java, C#, ABAP) simplify the collection of test coverage data.
- Architecture. The test-coverage data for a server-based application has to be collected from fewer machines than that for a fat-client application, for example.
- Testing process. Clearly defined test phases and environments facilitate planning and monitoring.
Using Test Gap Analysis During Hotfix Testing
The objectives of hotfix tests are to ensure that the fixed error does not re-occur and that no new errors have been introduced. To achieve the latter, we should at least ensure we tested all changes made in the course of the hotfix. Usually, there is very little time to achieve this.
With Test Gap Analysis, we may define the release state (before the hotfix) as the reference version and detect all changes made due to the hotfix (for example, on a dedicated branch). We then determine whether all changes were actually tested during confirmation testing. A Test Gap tree map immediately shows whether there are any untested changes left.
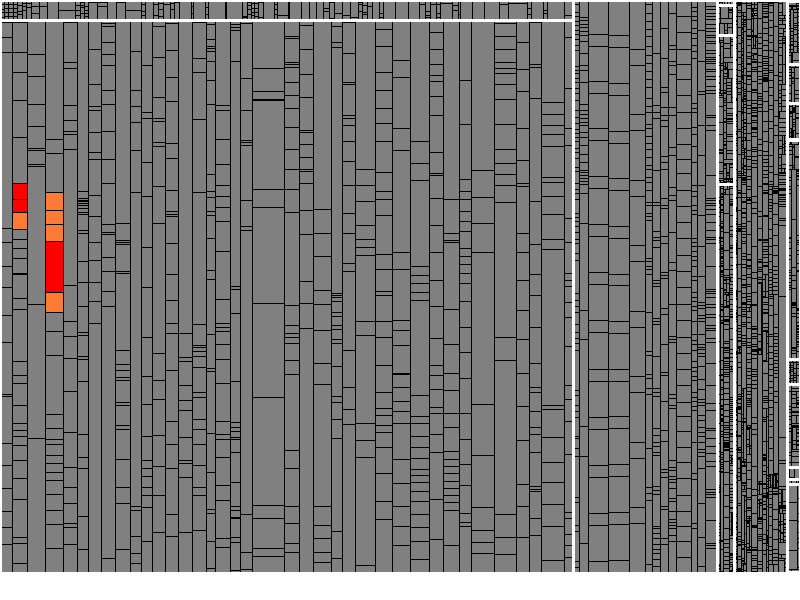
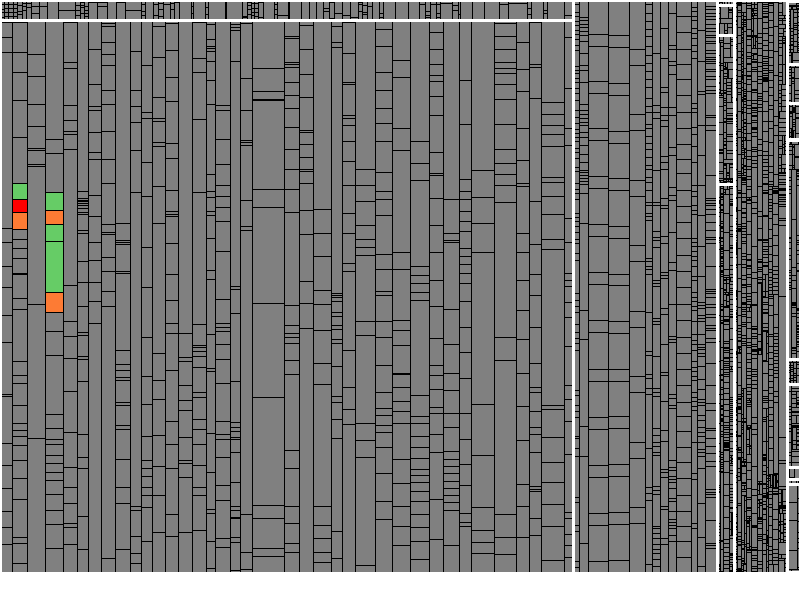
Figure 5b: Remaining untested changes (orange & red) and tested changes (green).
In our experience, Test Gap Analysis specifically helps avoid new errors that are introduced through hotfix changes.
Using Test Gap Analysis During a Release Test
For this scenario, we define a release test as the test phase prior to a major release, which usually involves both testing newly implemented functionality and executing regression tests. Often, this involves different kinds of tests on multiple test stages.

In the introduction to Test Gap Analysis above, we’ve looked at the results of running Test Gap Analysis at the end of a release test of an enterprise information system. These results revealed glaring gaps in the coverage of changes, after a test phase without using Test Gap Analysis to guide the testing efforts.
From that point onwards, Test Gap Analysis became an integral part of the testing process and was executed regularly during subsequent release tests. The following is a snapshot of the Test Gap Analysis during a later release test. It is plain to see that it contains much fewer Test Gaps.


If testing happens in multiple environments simultaneously, we may run Test Gap Analysis for each individual environment separately. And at the same time, we may run Test Gap Analysis globally, to assess our combined testing efforts. The following example illustrates this for a scenario with three test environments:
- Test is the environment in which testers carry out manual test cases.
- Dev is the environment where automated test cases are executed.
- UAT is the User Acceptance Test environment, where end users carry out exploratory tests.
- All combines the data of all three test environments.
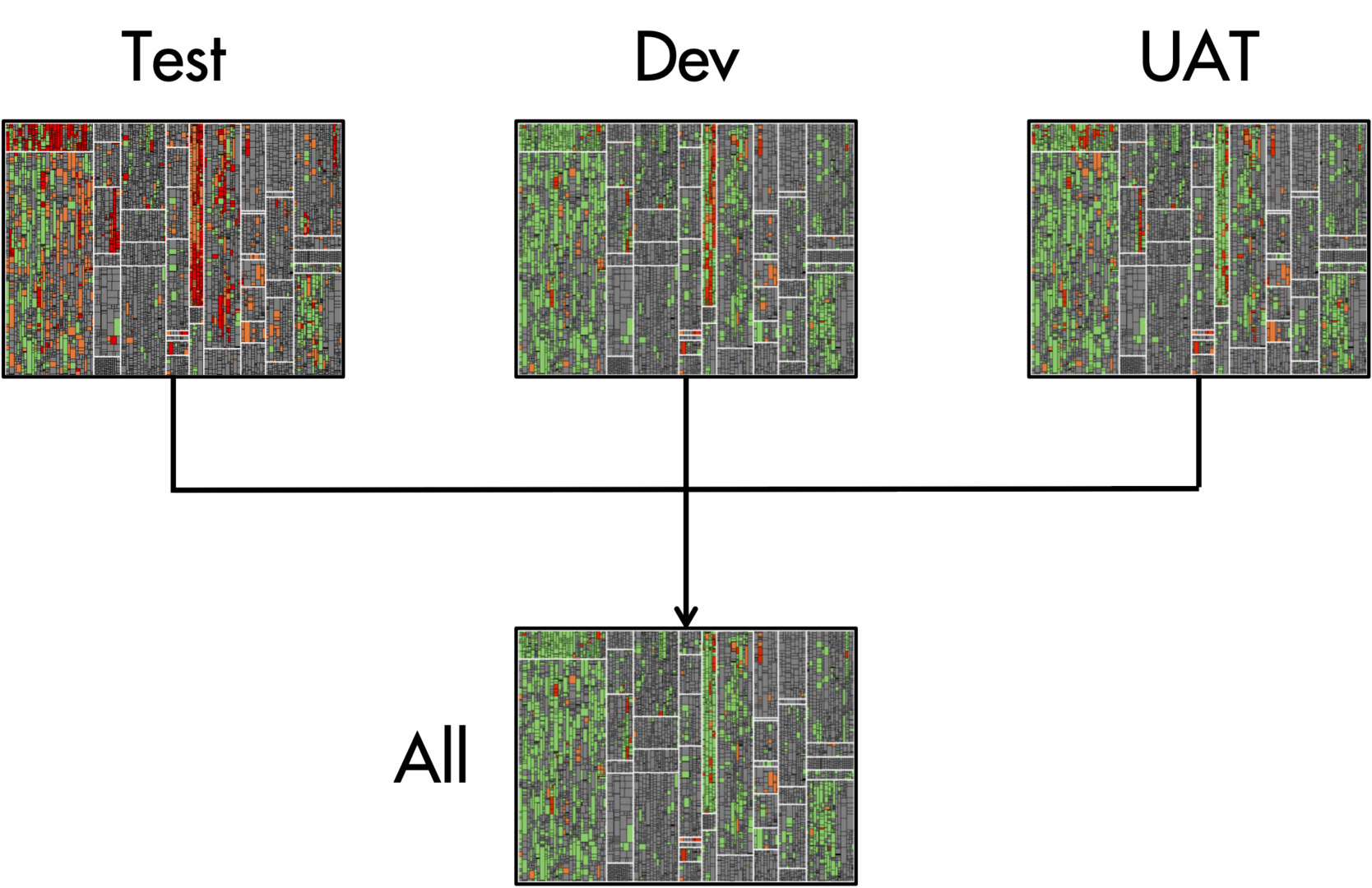
We observed that, in many cases, some Test Gaps are accepted, for example, when the corresponding source code is not yet reachable via the user interface. The goal of using Test Gap Analysis is not to test every single change at all cost. The key is that we can make conscious and well-founded decisions with predictable consequences about what to test.
In our experience, Test Gap Analysis significantly reduces the amount of untested changes that reach production. In a study with one of our customers, we found that this reduces the number of errors in the field by as much as 50%.
Using Test Gap Analysis Alongside Iterative Development
Today, fewer and fewer teams work with dedicated release tests, like in the previous scenario. Instead, issues from their issue trackers move into the focus of test planning, to steer testing efforts alongside iterative development.
In this scenario, testers are responsible to test individual issues in a timely manner after development finishes. As a result, development and testing interleave and dedicated test phases become obsolete or much shorter.

At the same time, it becomes even harder to keep an eye on all changes, because much of the work typically happens in isolation, e.g., on dedicated feature branches, and gets integrated into the release branch only on very short notice. All the more, we need a systematic approach to keep track of which changes have been tested and in which test environments.
Fortunately, we may run Test Gap Analysis also on the changes made in the context of individual issues. All we need to do is single out the changes that happened in the context of any particular issue, which is straightforward, e.g., if all changes happen on a dedicated feature branch or if developers annotate changes with the corresponding issue numbers when committing them to the version control system. Once we grouped the changes by issue, we simply run Test Gap Analysis for each of them.
Limitations of Test Gap Analysis
Like any analysis method, Test Gap Analysis has its limitations and your knowledge of them is crucial for making the best use of the analysis.
One of the limitations of Test Gap Analysis are changes that are made on the configuration level without changing the code itself. These changes remain hidden from the analysis.
Another limitation of Test Gap Analysis is the significance of processed code. Test Gap Analysis evaluates which code was executed during the test. It cannot figure out how thoroughly the code was tested. This potentially leads to undetected errors despite the analysis depicting the executed code as “green”. This effect increases with the coarseness of the measurement of code coverage. However, the reverse is as simple as it is true: red and orange code was not executed in tests, thus, no contained errors can have been found.
Our experience in practice shows that the gaps brought to light when using Test Gap Analysis are usually so large that we gain substantial insights into weaknesses in the testing process. With respect to these large gaps, the limitations mentioned above are insignificant.
Further Information
Test Gap Analysis may greatly enhance the effectiveness of testing processes. If you would like to learn more about how Test Gap Analysis works in our analysis platform Team scale, the first tool that offered Test Gap Analysis and, to date, the only tool providing Test Gap tree maps, as you have seen them above, check out our website on Test Gap Analysis or join our next workshop on the topic (online & free)!
References
[1] Sebastian Eder, Benedikt Hauptmann, Maximilian Junker, Elmar Juergens, Rudolf Vaas, and Karl-Heinz Prommer. Did we test our changes? assessing alignment between tests and development in practice.
In Proceedings of the Eighth International Workshop on Automation of Software Test (AST’13), 2013.
[2] N. Nagappan, Th. Ball, Use of relative code churn measures to predict system defect density, in: Proc. of the 27. Int. Conf. on Software Engineering (ICSE) 2005
Authors

Dr. Elmar Jürgens
(juergens@cqse.eu) is founder of CQSE GmbH and consultant for software quality. He studied computer science at the Technische Universität München and Universidad Carlos III de Madrid and received a PhD in software engineering.

Dr. Dennis Pagano
(pagano@cqse.eu) is consultant for software and systems engineering at CQSE. He studied computer science at Technische Universität München and received a PhD in software engineering from Technische Universität München. He holds two patents.

Dr. Sven Amann
(amann@cqse.eu) is a consultant of CQSE GmbH for software quality. He studied computer science at the Technische Universität Darmstadt (Germany) and the Pontifícia Universidade Católica do Rio de Janeiro (Brazil). He received his PhD in software technology from Technische Universität Darmstadt.
CQSE is an EXPO exhibitor at EuroSTAR 2023, join us in Antwerp.