
Why AI Needs a Multimodal Test Strategy!
It seems as though every organization is infusing artificial intelligence (AI) into its applications and processes these days. And why wouldn’t they? Generative AI and large language models (LLMs) have made it easy to integrate AI and machine learning (ML) capabilities into digital experiences, tools, frameworks, platforms, and more.
Some of these AI-based systems are now multimodal, meaning they combine different forms of data to make predictions and draw insights about real-world problems. Multimodal AI trains on and utilizes a combination of images, video, text, speech, audio or numerical data. For example, GPT-4 Turbo makes it possible to feed an image to the model with a text prompt, or request that visuals be used to support an explanatory response.
Beyond the context of AI (pun intended!), multimodality simply refers to activities having different modes. As such, there are many things that can be described as multimodal. Software testing, for example, is multimodal because there are several types of testing, each with formal and informal techniques, methods, and supporting tools. However, for many years the testing industry has been focused on what I consider to be a single mode of testing — pre-production testing. That is, testing that occurs prior to the release of a system or component.
Proponents of the shift-left testing mindset, including myself, advocate for paying attention to quality as early as possible in the software development lifecycle to reduce the cost and impact of late or escaped defects.
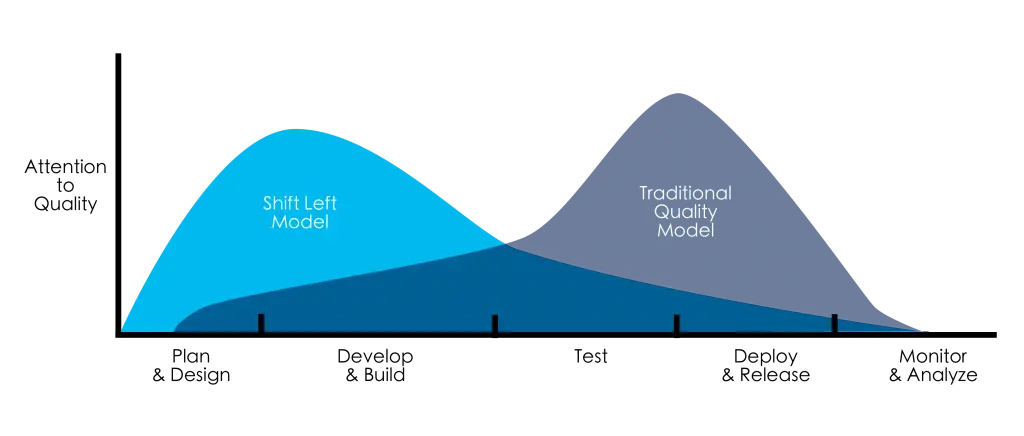
For AI-based systems, a pre-release testing strategy that emphasizes shifting left is important. However, because of its dynamic nature, it is equally important to test AI on the right, post-release, commonly referred to as production testing. This is the first article in a two-part series that describes a multimodal testing strategy for AI based on one of our mantra’s at Test IO — Shift-Left, Test Right!
Shifting AI to the Left
So what does a shift-left, pre-production testing model for AI systems look like?
It starts with understanding that a good testing strategy for AI must be holistic, and include the perspectives of product, engineering, data science, testing, performance, security, operations and the end user community.
A Holistic Quality Perspective for AI
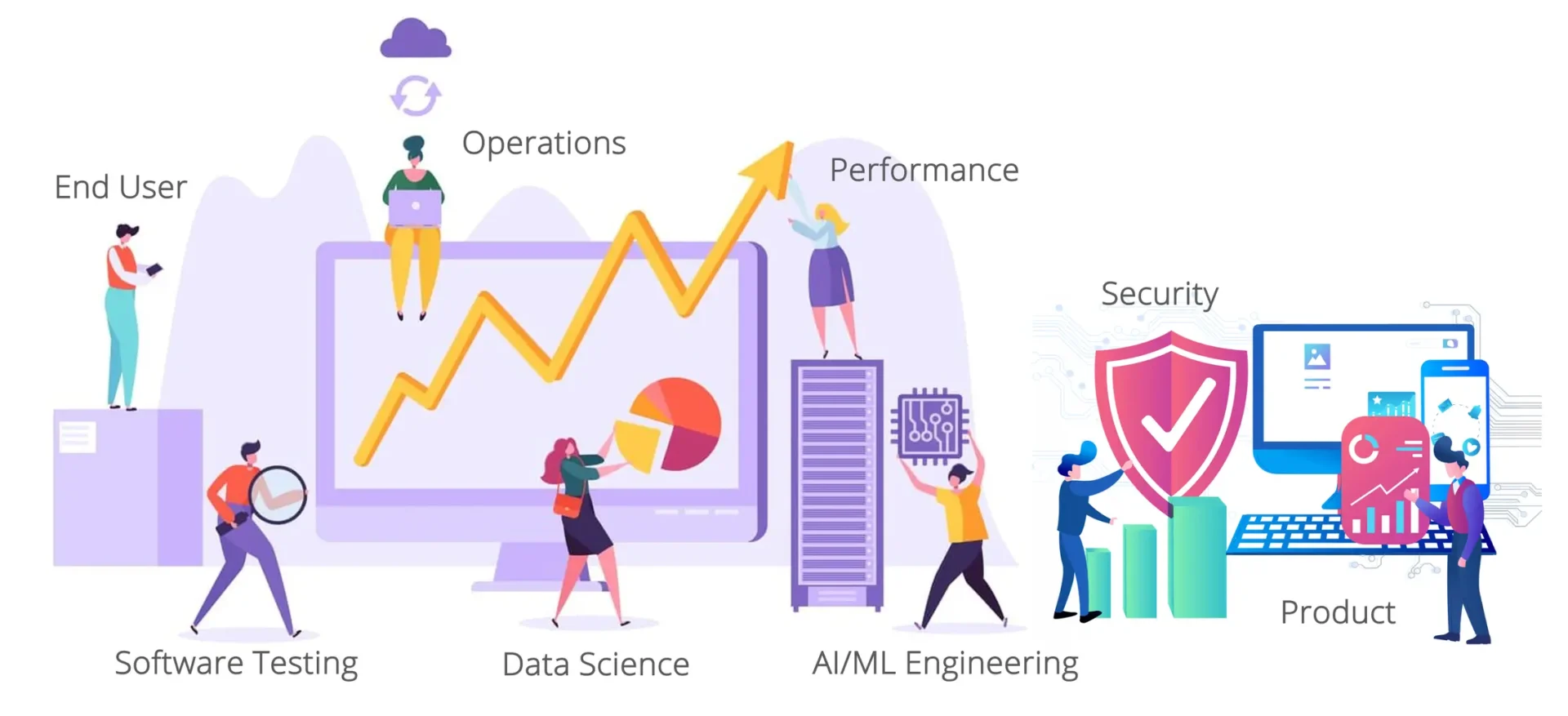
With key stakeholders at the table, you can now begin applying a systematic, disciplined, and quantifiable approach to AI software development.
Foundational AI Engineering Practices
In 2019, the Software Engineering Institute (SEI) of Carnegie Mellon University published a set of Foundational Practices for AI Engineering. Here are a few of them that I paraphrased and can attest to have lived out in a former life as a Chief AI Scientist:
- AI Problem First, Then Solution — Leveraging AI may often result in a more complex and expensive solution than a non-AI alternative, and therefore it is important to start with a well-defined problem that requires an AI solution. On the upside, the resulting AI solution may end up being more robust so it is important to weigh all of these factors into your decision.
- Choose Algorithms Based on Needs, Not Popularity — Select algorithms based on their appropriateness for solving the problem being tackled, not on their popularity. AI and ML algorithms may differ in the kinds of problems they address, level of detail of the output, interpretability, and robustness. Avoid using algorithms as “shiny new toys” and only change them to meet the needs as the system evolves or to adapt it to a new environment.
- Rule Your Data, Or Be Ruled By It — The output of an AI system is generally tied to the data used to train it. If you don’t take your data seriously it can consume the entire project. Make sure you allocate sufficient time and effort for managing your data, accounting for the need for data ingestion, cleansing, protection, validation, testing, and monitoring.
- Design AI for Ethics and Security — While data collection often raises questions concerning the privacy of AI, there are other ethical issues that should be addressed early during development. These include both fairness in data representation and decision-making based on diversity factors such as age, gender, ethnicity, disability, and more.
- Implement Flexible, Extensible Solutions — The boundaries of components in an AI-based system are more sensitive to change than those in traditional software. This is because data dependencies in AI systems may trigger changes in the expected outputs, system functionality, and infrastructure. It is therefore imperative to implement loosely coupled, flexible solutions to be able to keep pace with inevitable changes in the data, models, and algorithms.
To ensure that the aforementioned AI engineering practices are followed and implemented correctly, there should be validation and verification at each stage of the development process. In other words, the notion of continuous testing must be applied to AI software development.
Continuous Testing During AI Development
Applying continuous testing to AI development may require bringing a testing mindset to the stakeholders involved in development and/or having testers wear multiple AI development-related “hats”. Aspects of AI development that can be validated early as part of shift-left include testing the training process and testing the training data.
Testing the Training Process
Data scientists or AI/ML engineers are typically responsible for training the system. Although the strategy for continuous testing will depend on the specific type of machine learning being used, there is a general concern that should be addressed:
Model Fitting — during the training process, the selected model is fit on the training data in order to make predictions. In ML, fit refers to how well the model is able to approximate a given function. As shown in the figure, a model may be underfit, overfit or have a balanced fit.
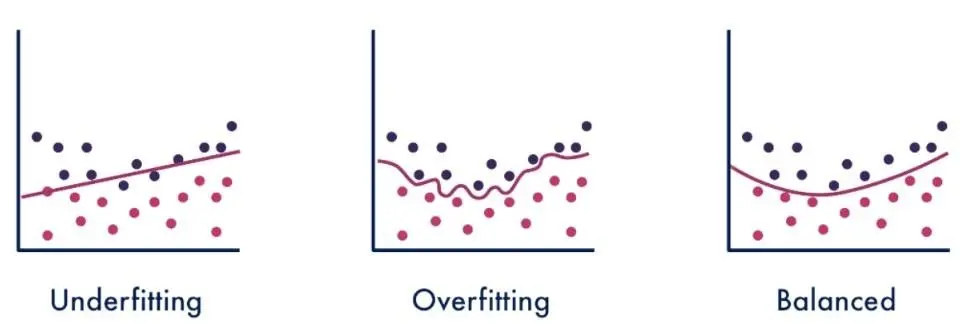
- Underfitting is when the model has not been trained enough and therefore misses the trends in the training data. This can happen if you have too little data or a very simple model.
- Overfitting is when the model how has been trained too much and therefore matches too closely to the training set. In such cases, the model may be capturing noise in the data instead of, or in addition to, the underlying data pattern. This can happen when the model trains too long or is too complex.
- Balanced Fitting is when the model has been trained “just right” and there it is a good approximation of the true function, which represents a solution to the problem under investigation.
Understanding the notion of model fitting repreents the tip of the iceberg when it comes to validating the training process. However, it should be clear that if testers are going to contribute to this aspect of shift-left, they will have to ramp up on data science and AI/ML engineering. Unlike the training process, data is an area of AI/ML that testers are likely to be able to add value to with little or no lead time.
Testing the Training Data
Software testers deal with data all the time, and although it may not be for the same purpose, many of the issues encountered with training data are similar to those for test data. Furthermore, a common technique for testing ML systems during development involves partitioning the dataset into a training set and a test set. Therefore, some of the data problems related to AI/ML development, directly correlate with the test data selection and test data management issues. These include, but are not limited to:
- Duplicate Data
- Outdated Data
- Incorrect Data
- Incomplete Data
- Inconsistent Data
- Insecure Data
- Non-Representative Data
The testing mindset provides on added superpower when it comes to data — the end user’s perspective. User empathy is commonly cited as one of the traits of a good tester. It enables one of the most important activities surrounding the validation of training data — assessing AI fairness.

One of the key goals of evaluating AI fairness is to answer the question: Are there groups of people who are disproportionately, negatively affected by the system. A quick AI fairness-related check is to inspect the sample size distribution of the input features and/or outcomes, especially for sensitive attributes like age, gender, race, among others.

Assessing AI fairness goes way beyond spot checking sample size distributions. In fact, most of the tech giants are associated with the development of tools and frameworks to support testing AI applications for fairness issues. These include Fairlearn, AI Fairness 360, and the What-If Tool.
Summary
This article explored the concept of shift-left testing as it may be applied to AI systems. Shifting AI to the left requires thinking holistically about testing these types of systems, and rooting their development in foundational engineering practices. Validation of the training process and training data, among other activities, should be integral to AI development. However, this type of pre-production testing for AI only represents a single-mode of activities.
Stay Tuned.
Author

Tariq King, CEO and Head of Test IO
Tariq King is a recognized thought-leader in software testing, engineering, DevOps, and AI/ML. He is currently the CEO and Head of Test IO, an EPAM company. Tariq has over fifteen years’ professional experience in the software industry, and has formerly held positions including VP of Product-Services, Chief Scientist, Head of Quality, Quality Engineering Director, Software Engineering Manager, and Principal Architect. He holds Ph.D. and M.S. degrees in Computer Science from Florida International University, and a B.S. in Computer Science from Florida Tech. He has published over 40 research articles in peer-reviewed IEEE and ACM journals, conferences, and workshops, and has written book chapters and technical reports for Springer, O’Reilly, Capgemini, Sogeti, IGI Global, and more. Tariq has been an international keynote speaker and trainer at leading software conferences in industry and academia, and serves on multiple conference boards and program committees.
Outside of work, Tariq is an electric car enthusiast who enjoys playing video games and traveling the world with his wife and kids.
EPAM is an Exhibitor at EuroSTAR 2024, join us in Stockholm.