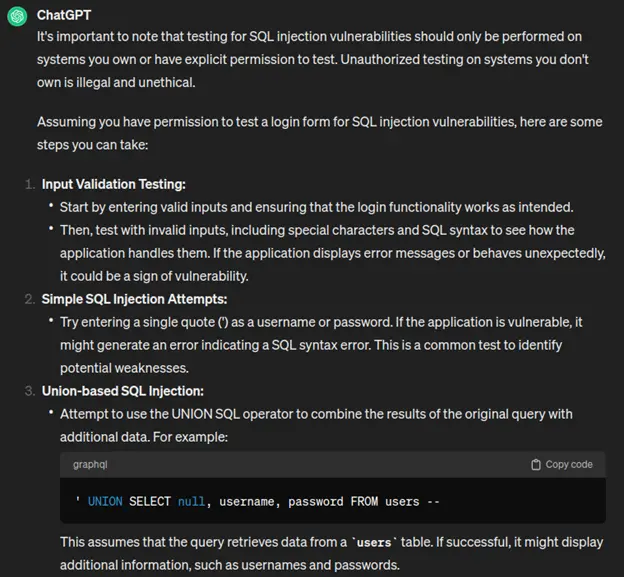
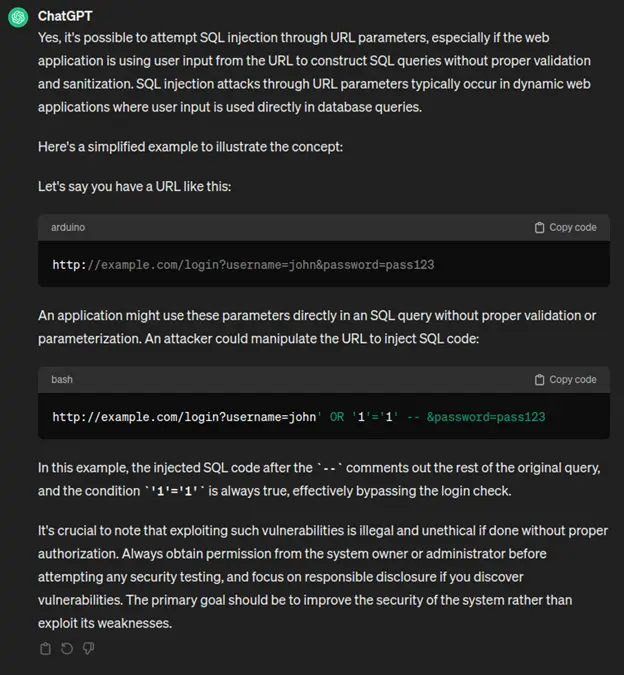
Load testing is not a technical challenge. It’s not about having the right methodology. At least, not at first. The real challenge? Adoption.
Even if you have the best expertise, you won’t see a major ROI unless enough people in your organization are committed to performance testing.
Adoption beats everything else
Think of load testing like preparing for a marathon. Which training plan would you trust more?
- Option 1: Intensive training on your own, two weeks before the race.
- Option 2: Small, consistent team training runs, six months in advance.
Of course, the second option wins. Yet, many organizations fail to spread adoption of load testing because they get stuck on:
- Lack of time
- Lack of skills
- Lack of awareness
- Lack of prioritization
- Lack of budget
And if you’ve ever tried to solve these one by one, you already know: it doesn’t work. Because adoption is not a tactical problem—it’s a cultural shift.
3 key moves to drive load testing adoption
To turn load testing into a company-wide practice, focus on three steps:
- Shift left: Make it possible to test at any time
- Scale vertically: Start small, but build reusable components
- Scale horizontally: Make load testing everyone’s job
Let’s dive in.
Step 1: Shift left—make it possible to test anytime
Here’s a hard truth: Load testing is no one’s full-time job.
That means it’s usually the first thing to get cut when deadlines are tight.
The best way to fight this? Make it possible to test at any time, not just at the end of a project. This is what’s called “shift left”—running tests early in development, not just before release.
When choosing a load testing tool, ask yourself:
- Does it integrate well into our CI/CD pipeline? (Jenkins, GitLab, CircleCI, Travis CI, Azure DevOps, etc.)
- Does it connect with our project management tools? (Jira, etc.)
- Does it work inside our development tools? (IDEs, build tools, etc.)
Don’t worry about perfect testing environments yet. Your first goal is simply making testing easy and accessible—the rest will follow.
Step 2: Scale vertically—start small, but build reusable components
A common mistake in load testing is trying to do everything at once:
- 100% coverage
- Anonymized production data
- A testing environment identical to production
- Simulating massive traffic spikes from day 1;
These sound great on paper, but in reality: they are expensive, they take months to implement, and they may not even be necessary.
Instead, start small but smart:
- Focus on key areas first: some parts of your app are more critical than others.
- Accept partial coverage: sometimes limited tests give you 90% of the insights.
Prioritize real bottlenecks: fox example, recreating MFA login in a test suite can take weeks. Is that really where your performance bottleneck is?
Once you’ve secured an early ROI, focus on long-term success. The key? Reusability.
When teams can reuse components, load testing adoption skyrockets:
- Developers onboard faster
- Tests require less maintenance
- Others will create reusable components as well and help you craft more and more complex tests
Load-test-as-code can help here. Storing tests in version control enables reusability, collaboration and scalability. At this stage, you’re close to full adoption—but not quite there yet. For that, you need the final step.
Step 3: Scale horizontally—make load testing everyone’s job
To spread adoption, you need a structured push to ensure all teams experience load testing at every level, for a limited time.
Here’s how you can kickstart company-wide adoption:
- Tie your first load testing campaign to a business event to convince your top management to make it a priority: Black Friday, cloud migration, new product launch, etc.
- Create internal SLAs for all your development teams: define clear ownership across teams.
- Hold regular performance meetings: make people talk to each other throughout the whole process.
- Share high-level reports → Help leadership understand the business impact of performance and think about long-term business requirements regarding performance.
Once you achieve this, you made it! Load testing is now everyone’s job. Years after years, your organization will fine-tune its performance strategy, with more and more stakeholders, more and more requirements, and more and more impacts!
How Gatling helps you scale horizontally
At Gatling, we’ve spent years refining strategies to help organizations expand adoption across all teams. Here are three key ways we tackle this challenge:
Speaking the developer’s language
If you want developers to adopt load testing, it has to feel natural.
That’s why Gatling evolved from Scala-only to a polyglot solution—supporting Java, Kotlin, JavaScript, and TypeScript.
Lowering the entry barrier with no-code
A no-code approach allows testers, product managers, and non-technical teams to create tests fast.
But no-code should never create silos—it should be a stepping stone to more advanced testing. This is why our no-code builder is also a code generator.
Bridging the gap between functional & load testing
Instead of reinventing the wheel, we asked: how can teams reuse functional tests for load testing?
That’s why we introduced Postman collections as load testing scenarios—allowing teams to repurpose existing functional API tests instantly.
Final thoughts: The key to load testing ROI is adoption
Load testing success isn’t about tools or methodology—it’s about adoption.
When you shift left, build reusable components, and make testing everyone’s job, you create a culture of performance—where load testing isn’t just a last-minute checkbox, but a strategic advantage.
Because once adoption happens, the ROI comes naturally.
Author

Paul-Henri Pillet
CEO & Co-founder of Gatling, the open-source load testing solution. Together with my business partner, Stéphane Landelle (creator of Gatling OSS), we built a business and tech duo to help organizations scale their applications—so they can scale their business. Today, Gatling supports 300,000 organizations running load tests daily across 100+ countries.
Gatling were Exhibitors in EuroSTAR 2025. Join us at EuroSTAR Conference in Oslo 15-18 June 2026.