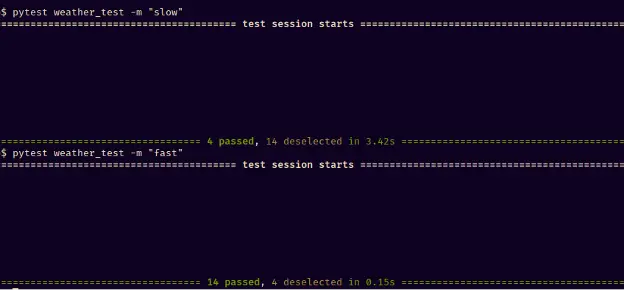
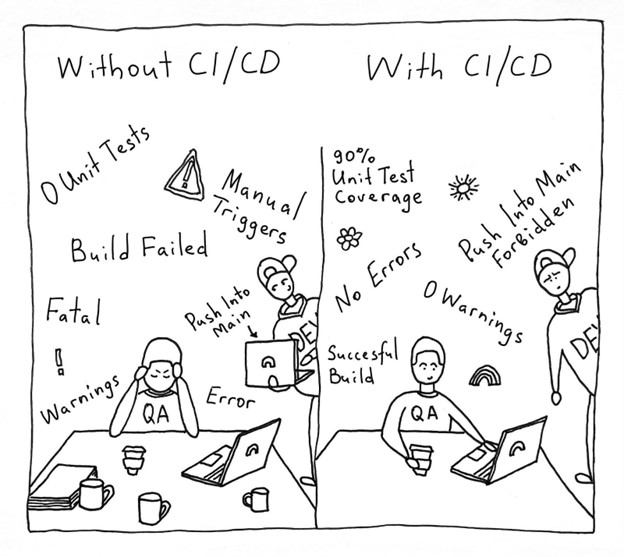
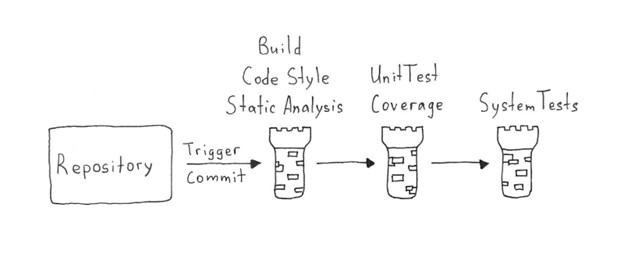
In an era marked by rapid digital transformation, the quality of software products has emerged as a linchpin of success for companies across the globe. Digital natives, who represent future generations, are shaping market trends more than ever before, leading to a high demand for flawless, easy-to-use, and feature-packed products. In today’s evolving landscape, organizations need to rethink their approach to do quality assurance (QA) and product testing, recognizing the necessity of integrating native quality management with crowdtesting methodologies. This holistic integration ensures comprehensive coverage and adaptability to meet the demands of today’s dynamic market.
The Imperative for a Quality-Centric Culture
The cost of neglecting quality in software development can be staggering. Companies that fail to cultivate a culture deeply rooted in quality management face not only financial losses from rectifying errors but also damage to their brand reputation and customer trust. A quality-centric culture is not merely about detecting and fixing bugs; it’s about embedding quality into every phase of the development lifecycle, from initial design to final release and further iterations. Adopting a native quality management approach involves seamlessly integrating QA processes with development workflows, ensuring that QA and development teams collaborate closely.
Crowdtesting: Leveraging the Power of Real-World Feedback
As the digital landscape becomes increasingly user-driven, understanding and meeting the diverse needs of various user segments is critical. Crowdtesting emerges as a powerful solution to this challenge, enabling organizations to test their products in real-world scenarios across the big number of devices, operating systems, and user environments. This approach not only validates the functionality and usability of products but also uncovers nuanced insights into user preferences and behaviors, facilitating a deeper connection with the target audience. Crowdtesting bridges the gap between theoretical QA and practical, user-centric validation. By engaging a targeted group of users from the intended market segment, companies can gather actionable feedback on their products’ performance, usability, and appeal. This method provides a more nuanced understanding of subjective user experiences, enabling developers to refine their products in ways that resonate with their audience’s expectations and preferences.
Integrating Quality Management and Crowdtesting
The integration of native quality management and crowdtesting represents a comprehensive strategy for achieving excellence in software development. This dual approach ensures that quality is not only baked into the development process but also validated through extensive, real-world testing. By measuring quality maturity and incorporating crowdtesting feedback early and throughout the product lifecycle, companies can anticipate and mitigate potential issues, streamline their development processes, and enhance product quality. Such an integrated approach also fosters a culture of continuous improvement and innovation. As teams become more aligned on quality objectives and gain insights from direct user feedback, they are better equipped to make informed decisions, prioritize features, and deliver products that truly meet, if not exceed, user expectations.
Conclusion: The Future of Software Development is User-Driven
The digital age demands a new paradigm in software development—one that places quality and user experience at the forefront. By embracing a quality-centric culture and integrating crowdtesting into the product development lifecycle, companies can navigate the complexities of modern software development more effectively. This strategic imperative not only enhances product quality and user satisfaction but also positions companies for sustained success in a competitive digital marketplace. As we look to the future, crowdtesting will undoubtedly become a cornerstone of successful software development. It promises not just better products but also a deeper understanding of the ever-evolving digital consumer, ensuring that companies can continue to innovate and thrive in the digital age.
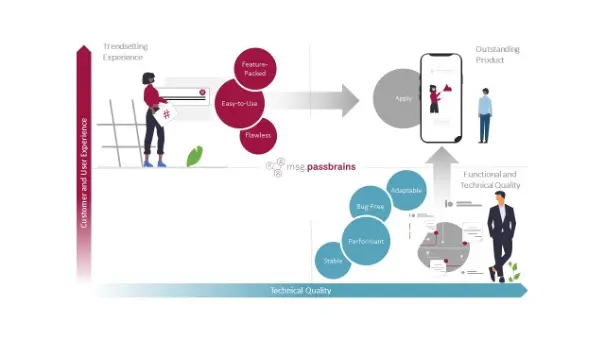
Figure. 1: The next Level of digital excellence: Embrace Crowdtesting
Author

Stephan Ingerberg, Head of Sales, msg Test & Quality Management
Stephan Ingerberg is a seasoned professional with over a decade of experience in the realm of software quality and digital assurance. He is a dedicated desciple of quality and testing since 2004.
Currently serving as a pivotal figure in the Test & Quality Management division of msg, responsible for sales, customer relations and commercial aspects within central Europe. His unwavering dedication to excellence and adept navigation of software quality make him indispensable in the pursuit of digital perfection.
https://www.linkedin.com/in/stephan-ingerberg-digital-transformation/
msg Test & Quality Management is an Exhibitor at EuroSTAR 2024, join us in Stockholm.