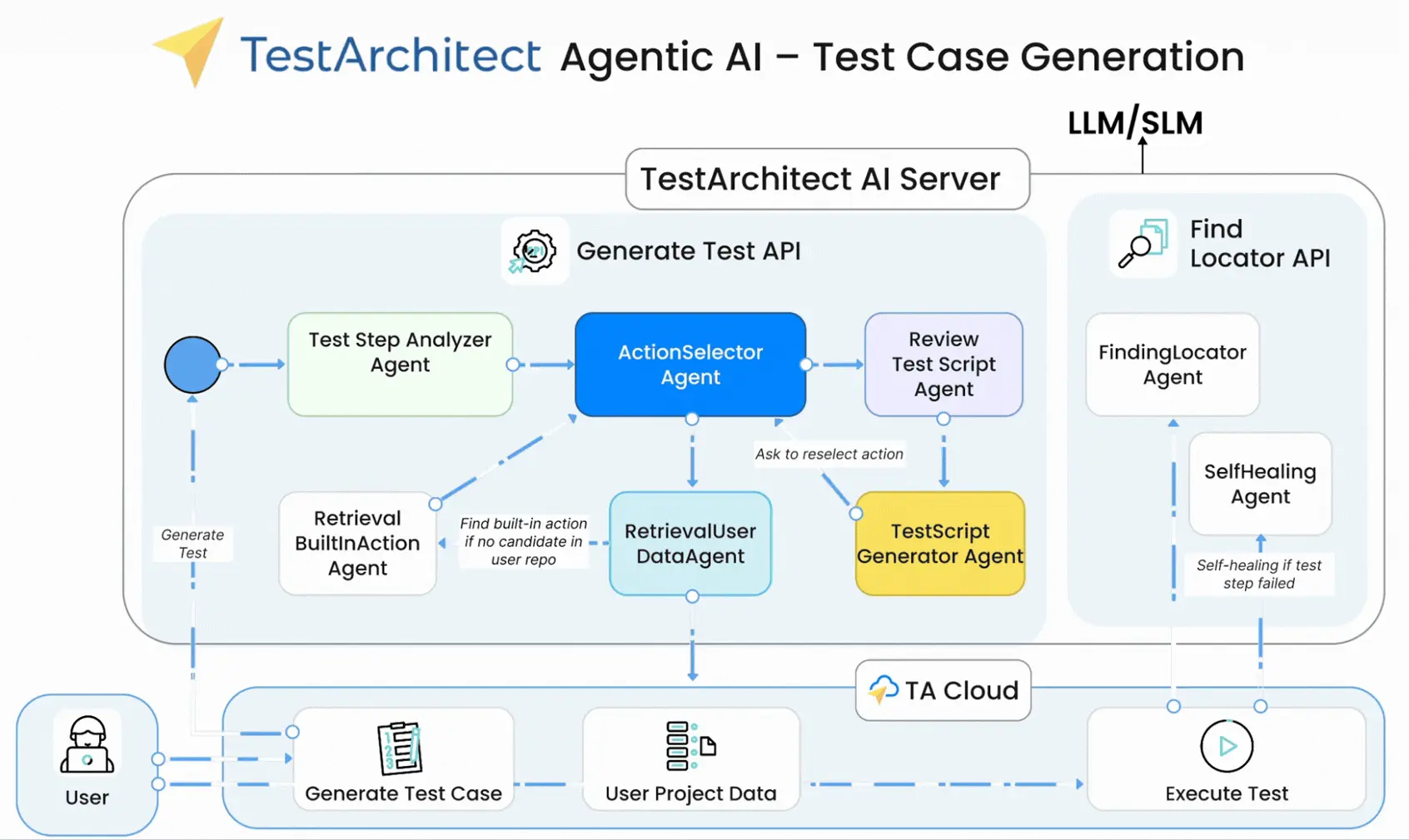
Run the same AI agent with the same input ten times. You will get ten different results.
Sometimes subtly different. Sometimes wildly.
That single fact breaks almost everything traditional QA was built on.
LangChain’s 2026 State of Agent Engineering report surveyed 1,300+ professionals. The
findings are stark: 57% of organizations now have AI agents in production. Quality is the number one barrier to deployment, cited by 32% of teams. And only 52% have any evaluation system in place.
AI Agents Are in Production, but Evaluation Is Still Maturing
Do the math. Roughly half the organizations shipping agents to production have no structured way to know if those agents work reliably. For enterprises with 10,000+ employees, the top concern is not cost or speed. It is hallucinations and output consistency.
Gartner’s 2025 Hype Cycle placed AI agents at the Peak of Inflated Expectations, noting that multi-agent workflows and model non-determinism may trigger cascading failures.
That confidence gap is where QE teams should be rushing in.
Why the Input–Output Contract No Longer Holds
Traditional QA lives on a simple promise: given input X, expect output Y. AI agents break that promise by design. A customer service agent might resolve the same complaint through five different valid approaches. A coding agent might fix a bug with three different architectures. The output varies. The path varies. Both can be correct.
You cannot write an assertion that says “the response must equal this exact string.” You cannot build a regression suite expecting identical behavior across runs. And you cannot rely on pass-fail verdicts when the definition of “correct” depends on context, tone, and user intent. This is not a tooling problem. It is a thinking problem. And it demands that QE teams unlearn some deeply held assumptions about what testing looks like.
Define Behavioural Boundaries, Not Exact Outputs
The most effective teams testing AI agents have made a counterintuitive shift: they stopped checking exact outputs and started defining behavioural bounds.
Anthropic’s engineering team addressed this in their guidance. They recommend evaluating the quality of the final output rather than the exact steps taken to reach it. Agents often arrive at effective solutions through alternative paths. If evaluation frameworks reject those paths, the test suite becomes brittle instead of robust.
Practically, this means asking different questions. Did the agent call the correct tools? Did it stay within policy guardrails? Did it reach a valid end state? Did it handle edge cases without hallucinating?
Simulate Users, Not Just Inputs
Structured simulation frameworks help reduce production agent failures. The approach is simple: test agents against diverse user personas, communication styles, and edge cases before deployment.
A customer service agent that handles polite requests perfectly might collapse with ambiguous or frustrated users. A voice assistant tested only with clear enunciation will fail in noisy real-world environments. Testing AI agents means testing the full range of human unpredictability.
This is exactly the problem TestMu AI’s Agent-to-Agent Testing platform was built to solve. It uses specialized AI agents to simulate diverse personas, generate thousands of test scenarios, and validate how your agent handles conversation, reasoning, and context across real-world conditions.
The concept of using agents to test agents sounds recursive, but it is the only approach that scales to match the complexity of these systems.
Quality Is a Continuous Signal
Many teams approaching agent testing are moving beyond the idea of quality as a one-time, pre-release checkpoint. Instead, they treat it as an ongoing signal.
Production logs can inform new test cases. Real user interactions can expand scenario libraries. Evaluation can run continuously as agents evolve, helping teams adapt as behaviour changes over time.
LangChain’s data confirms this shift: 89% of teams have implemented observability for their agents. But observability without structured evaluation is just logging.
The winning practice combines automated monitoring to flag anomalies with human reviewers making judgment calls on ambiguous cases. Platforms like KaneAI support this continuous model. When test authoring, execution, reporting, and test management live in one unified system, the feedback loop from a production anomaly back to the relevant test scenario becomes fast and actionable, tight enough to drive real quality improvements.
The Discipline Is Being Rewritten
Quality engineering is expanding. As AI systems introduce probabilistic behavior, tool
orchestration, and adaptive workflows, the craft naturally grows more complex. Engineers who understand both testing fundamentals and AI system mechanics are well positioned to navigate that shift.
For teams already practicing strong QE, the shift is less about starting from scratch and more about refining the lens.
Author

Mudit Singh Co-Founder at TestMu AI
With over a decade of experience building and scaling
software products, he has helped shape quality engineering and AI-driven testing strategies that empower engineering teams to ship reliable software faster. His work spans product strategy, AI-native quality engineering, and community-led innovation, bridging the gap between human expertise and autonomous systems.
TestMu AI are Gold Sponsors at EuroSTAR 2026. Join us at EuroSTAR Conference in Oslo 15-18 June 2026.