End-to-end testing is one of the most effective ways software teams can understand the customer experience. Unlike unit or component testing, which focus on individual pieces of the application, E2E tests seek to understand product quality as an integrated journey. In many ways, end-to-end testing exemplifies the expanding role of software testing in a DevOps world: the crucial connection between how software is built and how it is used. When development teams understand how their changes will impact their end users, they’re better able to deliver value to those customers. When automated effectively, end-to-end testing provides this connection quickly enough to support continuous delivery.
But the shift to digital-first experiences means that end-to-end testing needs to evolve and expand, running contrary to established testing best practices. Even a simple user journey, such as the one outlined below, likely involves multiple third-party APIs and services as well as email touchpoints and personalized offers or recommendations. Development teams must build seamless user experiences that make a complex customer journey feel simple. Expanding the definition of end-to-end testing ensures they can do so successfully. But with traditional testing frameworks, complicated automated testing meant a high risk for broken tests, extra maintenance, and inaccurate results, which ultimately slowed down development pipelines. Quality teams instead opted for shorter, simpler end-to-end tests that were less likely to break as the product evolved. But the holistic view provided by true end-to-end testing is extremely valuable – if quality teams have the tools to manage them.
New Customer Journeys Demand Broader End-to-End Testing
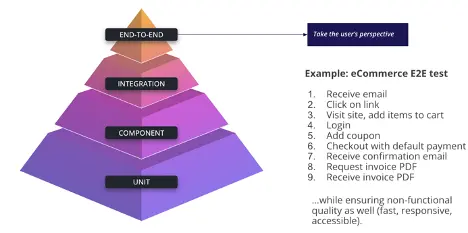
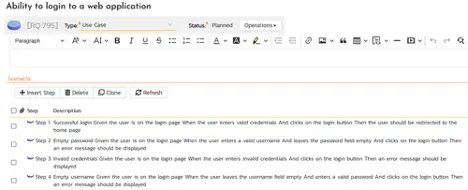
The image above includes an example of an end-to-end test for an ecommerce website. Despite this being a fairly simple – and common – transaction, an automated test needs to cover a marketing email, a coupon code, and an invoice email with a PDF attachment. But the story doesn’t end there: it’s extremely likely that the checkout test step includes an API for a payment service like Square or Afterpay. It’s also likely that coupon codes are personalized for customers, given that loyalty programs with customized rewards are proven to increase consumer spending.
Skip these steps, and there is a real risk to revenue. If a marketing email fails to accurately show a customer’s coupon code, conversion rates will suffer, impacting sales and potentially churning previously loyal customers. Managing this type of comprehensive test is essential for supporting quality customer experiences.
The Challenges of Comprehensive End-to-End Testing
Though the above end-to-end test is critical for understanding the user experience and how each change will impact it, such tests pose several challenges for developers and software testers. First, maintaining such an extensive automated test with scripted test automation frameworks is likely to consume a significant amount of a testing team’s time and effort, which has a serious impact on an organization’s ability to accelerate product velocity. Since additional test steps increase the risk of a test breaking, most quality teams avoid creating longer end-to-end tests in order to reduce the burden of test maintenance. But what they gain in reliability, they lose in test coverage.
Second, comprehensive automated tests often require longer investigations into failures. Combing through a long list of test steps to identify the specific cause of a test failure can take valuable hours, a luxury development teams don’t have as delivery cycles shorten. Considering that 44% of developers say that investigating failed tests is a significant pain point, quality teams must have effective strategies in place to triage comprehensive end-to-end tests when necessary.
Maintaining More Complex End-to-End Tests
An end-to-end test covering email, API, and non-functional test steps is highly susceptible to any product changes, but advances in AI and machine learning have reduced the amount of time and effort needed to maintain automated tests, making it possible for quality teams to manage comprehensive end-to-end tests. Using unique identifying elements across an application’s UI, including shadow DOM components, intelligent test automation solutions can detect product changes and update end-to-end tests accordingly.
Automating end-to-end test maintenance not only ensures that test maintenance is less labor-intensive, but also allows more team members to contribute. For example, manual testers can more easily collaborate on E2E tests that contain integrated API tests, ensuring that comprehensive end-to-end tests capture the full user journey and accurately assess quality.
Reporting on End-to-End Testing
Even when end-to-end tests are maintained, identifying the root cause of an error can be time-consuming, causing delays and disruptions in the later stages of the SDLC. Rapid results that support fast bug resolution is critical for delivering exceptional user experiences at the speed of DevOps.
Advances in cloud-based testing and the availability of SaaS test automation tools are making it easier to scale and maintain comprehensive end-to-end testing strategies. Cloud-based runs give in-depth insights that support continuous improvement, and can be run on a schedule or as part of a CI/CD pipeline. Flexible execution options make it possible to routinely and reliably run comprehensive end-to-end tests without slowing development. But perhaps even more importantly, integrating end-to-end test automation into existing development workflows allows developers to quickly act on end-to-end test results.
Building workflows that surface comprehensive end-to-end test results in a digestible way supercharges their value. Sharing test results as Jira tickets, complete with screenshots of the point of failure, DOM snapshots, and performance logs, is ideal for triaging comprehensive end-to-end tests since developers can easily identify what test step caused the failure. The time from failure to fix becomes much shorter, making comprehensive end-to-end tests highly actionable.
The Future of End-to-End Testing
comprehensive end-to-end tests are often considered too time-consuming to provide real value to development teams. But their ability to ensure quality of the perspective of the customer is invaluable, even essential, in a time where every business is competing on their digital customer experience. Overcoming test maintenance, execution, and investigation obstacles to comprehensive end-to-end tests gives development organizations a powerful tool for understanding how changes will impact their users. And with the right test automation solution, end-to-end testing becomes an adaptable process that can continuously evolve to match real customer needs. A few examples include automated accessibility checks, integrated API tests, shadow DOM components, and cross browser testing. No matter what your customers need, comprehensive end-to-end tests will help your team deliver exceptional user experiences.
Author

Bridget Hughes., Content Marketing Manager at mabl
Bridget is the Content Marketing Manager at mabl, the unified test automation platform for delivering modern software quality. She’s dedicated to helping quality teams expand testing and improve product quality through educational blogs, articles, and the occasional software testing meme.
Mabl is an Exhibitor at EuroSTAR 2024, join us in Stockholm.